LES WEB SERVICES


I - La base de conception : SOA
Larchitecture des Web Services est principalement orientée autour du modèle SOA (Services Oriented Architecture) et pour beaucoup dailleurs, les termes SOA et Web Services sont des synonymes. Il existe tout de même une différence fondamentale entre les deux car SOA n'est pas en soit une technologie, mais plutôt un principe de conception, alors que les Web Services, sont eux, des implémentations technologiques.
SOA est une architecture logicielle mettant en uvre des connexions de couplage lâche entre divers composants logiciels appelés services. Par définition, un service a pour but de proposer, en faisant éventuellement appel à dautres services complémentaires ou concurrents, un résultat particulier en fonction des informations qui lui ont été envoyées par les tiers. Chacun de ces services, dont les interfaces et les contrats d'utilisation sont obligatoirement connus, répond à des spécifications précises et est considéré en tant que processus métier.
SOA est né en réponse aux problèmes des systèmes existants qui étaient beaucoup trop liés à un langage ou une plateforme particulière et qui ne permettaient aucune évolution sans causer le disfonctionnement de certaines fonctionnalités et une augmentation drastique des coûts de maintenance.
L'idée de base a donc été de considérer quun système d'information était composé de différentes briques fonctionnelles offrant chacune des services à l'ensemble des autres briques. Chaque brique devenant alors responsable de ses données et des règles métiers qui en régissent.
Il n'existe pas à proprement parler de spécifications officielles d'une architecture SOA, néanmoins, comme la mise en uvre de connexions en couplage lâche implique obligatoirement l'utilisation d'interfaces d'invocation et de description de données communes, certaines caractéristiques apparaissent :
Ø la notion de service : c'est-à-dire une fonction encapsulée dans un composant que l'on peut interroger à l'aide d'une requête composée d'un ou plusieurs paramètres et fournissant une ou plusieurs réponses. Idéalement chaque service doit être indépendant des autres afin de garantir sa réutilisabilité et son interopérabilité,
Ø la description du service : consiste à décrire les paramètres d'entrée du service ainsi que le format et le type des données retournées. Le principal format de description de services est WSDL (Web Services Description Language), normalisé par le W3C,
Ø la publication (advertising) et la découverte (discovery) des services : la publication consiste à publier dans un registre (registry ou repository) les services tandis que la notion de découverte recouvre la possibilité de rechercher un service parmi ceux qui ont été publiés. Le principal standard utilisé est UDDI (Universal Description Discovery and Integration), normalisé par l'OASIS (Organization for the Advancement of Structured Information Standards),
Ø l'invocation : représente la connexion et l'interaction du client avec le service. Le principal protocole utilisé est SOAP (Simple Object Access Protocol), lui aussi normalisé par le W3C.
Larchitecture SOA comprend trois composants principaux :
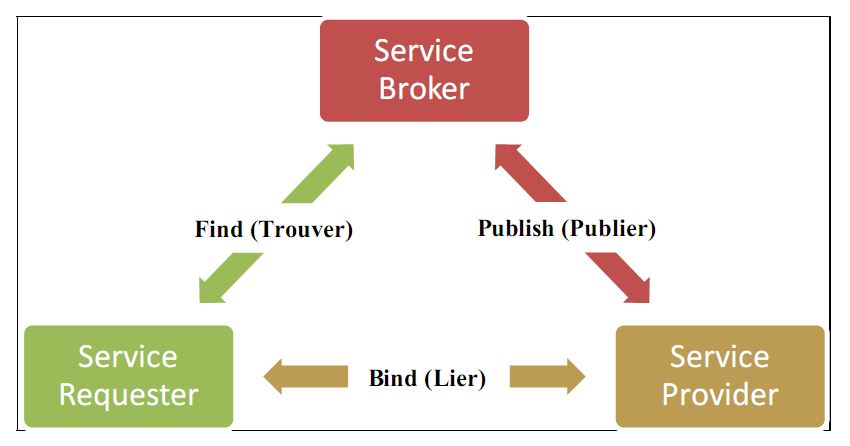
Ø le Service Provider est un élément du réseau dont la tâche est de fournir les interfaces des services correspondant aux logiciels quils représentent. Les composants Service Provider peuvent représenter aussi bien un logiciel bancaire complet qu'une simple unité de calcul ou encore un moteur graphique,
Ø le Service Requester est un élément qui permet de découvrir et dinvoquer les services dun composant Service Provider. Dans la mesure où SOA laisse les détails dimplémentations des couches "réseau" et "transport" ouverts, le développeur reste assez libre des choix quil devra faire et pour en résumer le rôle, celui-ci aura simplement à localiser le service, à y accéder et à interagir avec lui pour connaître le moyen de lutiliser,
Ø le Service Broker est un répertoire de services comparable aux pages jaunes dun annuaire. Cest au sein de ce composant que sont publiés et recherchés les composants. Lannuaire doit disposer dune taxonomie permettant la standardisation des informations concernant laccès et lutilisation du service. Il doit aussi fournir les différents moyens de publication et de localisation des services.
Larchitecture décrit également 3 rôles :
Ø publier (Publish) : à laide du Service Priovider qui envoi les informations au Service Broker,
Ø trouver (Find) : à laide du Service Requester qui demande les services aux courtiers (brokers),
Ø lier (Bind) : à laide du Service Broker qui assemble les modules pour permettre lexécution.
Le modèle darchitecture SOA, même si ce concept nest pas spécifique aux Web Services, a servit de base pour leurs conceptions. C'est ainsi que naquirent, après le premier accord de l'histoire entre tous les grands acteurs de l'informatique (Microsoft, IBM, SUN, Oracle, HP ), les protocoles SOAP, WSDL et UDDI utilisés par les Web Services, sapparentant respectivement aux Service Provider, Service Requester et Service Broker.
II - Principe de fonctionnement
Les Web Services sont une version améliorée des applications réparties, on dit aussi qu'ils en sont une version portable. Grace aux Web Services, il est maintenant possible d'effectuer des appels vers des applications distantes à travers le réseau Internet entier tout en reposant sur des standards ouverts. Attention tout de même à bien différencier un Web Services d'un service Web car même si leurs termes sont très ressemblants, ce sont deux choses bien distinctes. La différence fondamentale est que les services Web délivrent des pages Web destinées à une consommation humaine alors que les Web Services sont destinés eux à délivrer des données aux ordinateurs.
Les Web Services reposent principalement sur le protocole HTTP (ce qui leur permet de traverser les pare-feux) pour transporter les données et ils utilisent la technologie XML comme format de description et d'échange de message. Ils restent de cette manière à la fois indépendant du langage de programmation utilisé pour développer l'application et de la plateforme sur laquelle ils fonctionnent, c'est ce qu'on appelle le principe du couplage lâche ou du faible couplage.
Trois "méthodes" sont couramment utilisées pour ces échanges de données : SOAP, XML-RPC et REST. Les technologies SOAP et XML-RPC sont très proches car issues toutes deux du travail de Dave Winer. La différence repose dans le fait que SOAP est orienté objet et gère les états tandis que XML-RPC est procédural et sans gestion d'états. La méthode REST, quant à elle, est plutôt une nouvelle philosophie d'utilisation du Web qui prétend qu'une bonne gestion des URI est suffisante pour identifier n'importe quelle ressource située sur Internet et qu'utiliser les méthodes natives du protocole HTTP est largement suffisant pour interagir avec elles.
Les Web Services, quelles que soient leurs formes, utilisent également deux autres technologies qui sont WSDL et UDDI, pour pouvoir fonctionner. WSDL est une technologie qui permet de présenter une description complète du Web Services en langage XML (type de données acceptées, type de données retournées, son URL ) et UDDI est, quant à lui, une sorte d'annuaire permettant de classer et retrouver les Web Services.
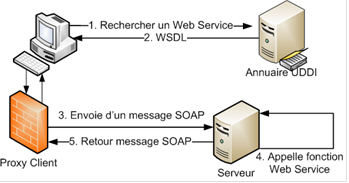
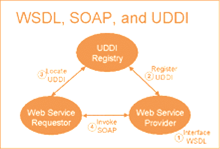
Le fonctionnement des Web Services repose donc sur un modèle en couches, dont les trois couches fondamentales sont :
Ø l'Invocation, pour décrire la structure des messages échangés par les applications,
Ø la Découverte, pour rechercher et localiser un Web Services particulier,
Ø la Description, pour décrire les interfaces d'un Web Services.
III - Les technologies en détail
3.1 - XML-RPC
Le standard XML-RPC est une surcouche applicative utilisant HTTP pour réaliser des échanges de type RPC (Remote Procedure Call) au moyen de documents XML. Il a été défini au sein de la société Userland Software par Dave Winer en réponse au développement par la société Microsoft du protocole SOAP, auquel il participait également, mais pour lequel il estimait que le développement était beaucoup trop long. La première version a été présentée en avril 1998.
La technologie XML-RPC repose, comme son nom le laisse présager, à la fois sur le langage XML et sur le protocole RPC. Le mélange de ces deux technologies a permis deffectuer des appels de procédures à distance à travers internet en restant, pour la première fois dans lhistoire de linformatique, totalement indépendant vis-à-vis de la plateforme ou du langage utilisé. XML-RPC permet d'appeler une procédure sur un serveur distant à partir de n'importe quel système (Windows, MacOs, Linux) et avec n'importe quel langage de programmation. Le serveur peut donc, lui aussi, reposer sur tout type de système et être programmé avec n'importe quel langage.
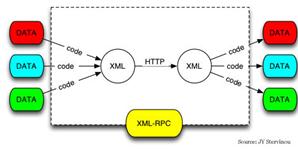
Contrairement à tous les protocoles dapplications réparties présentés précédemment, qui ne pouvaient qu'effectuer des échanges au format binaire, XML-RPC à ouvert la voie en permettant deffectuer des échanges, via HTTP, dans un formatage de haut niveau grâce à la sérialisation XML. Ainsi, XML-RPC a été conçu afin de permettre déchanger aussi bien des données de types simples que des tableaux ou des structures complexes. Au final, XML-RPC permet la manipulation et léchange de 8 types de données :
Ø int (entier signé),
Ø double (nombre signé double précision à virgule flottante),
Ø string (chaîne de caractères),
Ø boolean (bouléen: 0 = false et 1 = true),
Ø base64 (encodage binaire en base64),
Ø dateTime.iso8601 (date et heure au format ISO 8601 => ex: 19980717T14:08:55),
Ø array (tableau),
Ø struct (structure).
Une requête XML-RPC est donc un message utilisant le protocole HTTP et dont le corps est décrit au format XML. Ce message sera ensuite reçu puis traité par le serveur qui retournera la réponse lui aussi au format XML.
Voici un exemple de requête / réponse échangée via XML-RPC :
Ici nous allons appeler une méthode distante qui va simplement retourner une chaine de caractères en fonction du paramètre qu'on lui transmet. Par exemple, ce pourrait être un mot de passe provisoire attribué au pseudo de l'utilisateur transmit en paramètre (ici le pseudo "max17200" se voit attribuer le mot de passe provisoire "x7x7x7x7frr77v").
Ø La requête
POST /RPC2 HTTP/1.0
User-Agent: monagent
Host: www.monagent.org
Content-Type: text/xml
Content-length: 181
<?xml version='1.0' encoding='UTF-8'?>
<methodCall>
<methodName>
monsite.password_provisoire
</methodNam>
<params>
<param>
<value>
max17200
</value>
</param>
</params>
</methodCall>
Ø La réponse
HTTP/1.1 200 OK
Connection: close
Content-Length: 158
Content-Type: text/xml
Date: Tue, 22 Feb 2009 18:30:08 GMT
Server: OpenGesCom/1.0.1-Linux Debian
<?xml version="1.0" encoding="utf-8" ?>
<methodResponse>
<params>
<param>
<value>
<string>
x7x7x7x7frr77v
</string>
</value>
</param>
</params>
</methodResponse>
En-tête de la requête :
Le format de l'URI dans la première ligne de l'en-tête n'est pas obligatoire mais sa présence permet de router la requête XML-RPC vers le bon système d'écoute.
Le User-Agent et Host doivent être spécifiés, le Content-Type doit être de type "text/xml" et le Content-Length doit être lui aussi obligatoirement spécifié et correct.
Contenu de la requête :
Le contenu est en XML, et ne peut contenir quune seule balise <methodCall> qui elle même ne peut contenir quune seule balise <methodName>. La valeur contenue dans la balise <methodName> est obligatoirement de type chaîne de caractères et contient le nom de la méthode distante à invoquer. Ici on appelle la fonction distante "monsite.password_provisoire" et on lui transmet le paramètre "max17200".
En-tête et contenu de la réponse :
Sauf erreur, la réponse doit retourner "200 OK", le Content-Type doit être de type "text/xml" et le Content-Length doit obligatoirement être renseigné et correct.
La réponse renvoyée est une structure XML contenant la balise <methodResponse>. Cette méthode contient alors soit la balise <params> avec la réponse de la méthode en cas de réussite soit la balise <fault> dans le cas ou une erreur se serait produite. Une balise <methodResponse> ne peut contenir en même temps la balise <params> et <fault>. Dans le cas de notre exemple, la méthode a renvoyé la chaine de caractère "x7x7x7x7frr77v"
3.2 - SOAP
SOAP (Simple Object Access Protocol), initialement défini par Microsoft et IBM, est aujourd'hui devenu le protocole de référence pour l'envoi de messages dans le cadre d'architecture de type SOA pour les Web Services.
Tout comme XML-RPC, SOAP est un protocole de type RPC bâti sur XML mais il est, lui, orienté objet. Ces deux protocoles sont très proches car ils sont, comme nous venons déjà de le dire en présentant XML-RPC, issus du même moule qui est le travail de Dave Winer qui, en réponse au développement de SOAP au sein de Microsoft jugé trop long, avait décidé de créer sa propre version de SOAP quil baptisa XML-RPC.
SOAP a finalement été publié dans sa première version stabilisée en juin 1999 et les deux protocoles ont ensuite évolués chacun de leur coté. Ces deux protocoles garderont néanmoins à jamais un lien étroit car SOAP, qui est donc à lorigine de XML-RPC, en est aujourdhui devenu son successeur. La raison de la popularité grandissante de SOAP est principalement dû au soutient, tout dabord de Microsoft puis par la suite, du W3C qui est devenu le mainteneur officiel de la spécification depuis sa version 1.2 publiée en 2003.
Bien que reposant principalement sur HTTP du fait de sa popularité dans les technologies Web, SOAP nest pas lié à un protocole de transport particulier et peut très bien fonctionner par exemple avec SMTP, FTP ou encore tout autre protocole capable de véhiculer un flux d'information. SOAP est également indépendant du système dexploitation et du langage de programmation.
SOAP est un protocole suffisamment puissant et souple pour permettre d'encoder des structures de données de complexité de tous niveaux. Une des grandes forces de ce protocole est dailleurs de permettre aux développeurs d'adjoindre leurs propres spécialisations au sein des messages.
Un message SOAP est bien plus complexe quun simple fichier XML classique car il représente en réalité une déclaration très structurée, appelée "enveloppe", qui a elle seule, doit réussir à contenir la totalité des informations nécessaires à linvocation et lexécution de la fonction distante. Cette enveloppe est constituée d'un en-tête (header) facultatif et du corps du message (body). Ces deux éléments reposent fortement sur l'usage des espaces de noms afin de permettre le transport de tout type de contenu XML en évitant les conflits de noms d'éléments. Le squelette complet dun message SOAP prend la forme suivante :
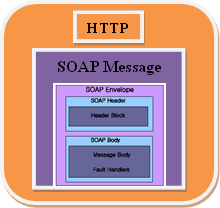
3.2.1 - L'enveloppe
C'est l'élément supérieur du document, il englobe l'en-tête et le corps du message. Cet élément est obligatoire et sans enveloppe, le message ne peut pas être transporté. Il doit également répondre comme étant qualifié, c'est-à-dire répondre à l'espace de noms définissant SOAP. Lenveloppe est lélément le plus externe, ou racine, dun message SOAP.
Ø L'en-tête
Placé au sein de l'enveloppe avant le corps, l'en-tête peut être utilisé pour compléter certaines informations nécessaires à une requête. Le plus souvent, on y trouve des extensions SOAP, des identifiants de connexion ou encore des métadonnées relatives au message. Les informations de l'en-tête peuvent être traitées, modifiées ou effacées par les applications intermédiaires. Pour assurer le bon traitement de ces informations, tous les éléments de Header doivent également être qualifiés par un espace de noms. L'en-tête reconnaît plusieurs attributs spécifiques :
Ø actor : permet d'indiquer le destinataire du message ou de viser une application intermédiaire spécifique via une URL,
Ø mustUnderstand : booléen qui permet d'indiquer si le traitement est obligatoire ou non,
Ø encodingStyle : permet de spécifier les règles d'encodage.
Ø Le corps
Cette section contient les données transportées par le message SOAP (le payload) qui, comme pour les éléments précédents, doit voir tous ses sous-éléments correctement qualifiés par des espaces de noms. Si c'est une requête, il doit contenir au minimum le nom de la méthode appelée, ainsi que les paramètres appliqués à cette méthode. En réponse, il contiendra soit un appel pour une autre méthode, soit une réponse à la requête, soit encore un message d'erreur détaillé.
Le protocole SOAP définit un mécanisme d'exception permettant de signaler la présence d'erreurs. Pour avertir dune erreur, SOAP utilise le sous-élément "Fault", qui lui-même dispose de quatre sous-éléments :
Ø faultcode : code identifiant de l'erreur,
Ø faultstring : explication lisible de l'erreur,
Ø faultactor : désigne l'origine de l'erreur,
Ø detail : donne des détails spécifiques.
Ø Types de données supportées en paramètre
Ø entier,
Ø date,
Ø booléen,
Ø chaîne de caractères,
Ø tableau,
Ø structure.
3.2.2 - Exemple
Nous allons maintenant voir un peu plus en détail ces messages. Pour cela nous allons simuler la méthode d'un service simple qui va doubler la valeur d'un entier quon lui transmet:
Ø Requête
<?xml version="1.0" encoding="UTF-8" standalone="no" ?>
<SOAP-ENV:Envelope
SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:SOAP-ENC="http://schemas.xmlsoap.org/soap/encoding/"
xmlns:xsi="http://www.w3.org/1999/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/1999/XMLSchema">
<SOAP-ENV:Header>
<ns1:AccountIdentifier> xissd42dfxx </ns1:AccountIdentifier>
</SOAP-ENV:Header>
<SOAP-ENV:Body>
<ns1: Fonction_double_entier_ Request xmlns:ns1="urn:MySoapServices">
<param1 xsi:type="xsd:int"> 123 </param1>
</ns1: Fonction_double_entier_ Request >
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
Ø Réponse
<?xml version="1.0" encoding="UTF-8" ?>
<SOAP-ENV:Envelope
xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsi="http://www.w3.org/1999/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/1999/XMLSchema">
<SOAP-ENV:Body>
<ns1: Fonction_double_entier_ Response xmlns:ns1="urn:MySoapServices"
SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/">
<return xsi:type="xsd:int">246</return>
</ns1: Fonction_double_entier_ Response >
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
Le prologue XML <?xml version="1.0" encoding="UTF-8" ?> spécifie la version de XML et l'encodage des caractères utilisés.
L'enveloppe SOAP <SOAP-ENV:Envelope ... > spécifie tout d'abord ici que le style d'encodage du message SOAP suit le schéma standard défini dans http://schemas.xmlsoap.org/soap/encoding/. Cest également ce schéma qui sera utilisé si aucun schéma nest spécifié. L'Enveloppe SOAP contient également des définitions d'espaces de noms. Il est important de savoir que les espaces de noms sont optionnelles mais quà partir du moment où ils sont définis, ils doivent être corrects.
Len-tête SOAP < SOAP-ENV:Header> comprend dans cet exemple une chaine de caractère qui servira didentifiant à lutilisateur. Les en-têtes SOAP sont optionnels et ne sont généralement utilisés que pour transmettre des informations d'authentification ou de gestion de session. Il est important de se rappeler que l'authentification et la gestion de session sont en dehors du cadre du protocole SOAP, même si SOAP en autorise la transmission.
Le corps SOAP <SOAP-ENV:Body> encapsule un unique tag qui porte le nom de la méthode invoquée <ns1: Fonction_double_entier ... >. Notez que le tag reçoit l'espace de noms correspondant au nom du service pour en assurer l'unicité. Le tag de méthode encapsule à son tour des tags <param> pour une requête et <return> pour une réponse. Les noms des tags <param> peuvent être modifiés.
L'une des caractéristiques les plus puissantes du protocole SOAP est sa capacité à gérer des paramètres de tout niveau de complexité. Voici pour le prouver, la réponse qui aurait été renvoyée si le rôle de la fonction distante nétait plus de retourner le double de lentier quon lui transmet mais plutôt de retourner un tableau de chaînes de caractères à deux dimensions contenant par exemple le nom et le numéro de téléphone dune personne dont lidentifiant serait lentier transmis. La requête dinvocation de la fonction distante, hormis le nom de la fonction invoquée qui a changé, reste identique. Par contre la réponse retourne maintenant un tableau à deux dimensions.
Ø Réponse
<?xml version="1.0" encoding="UTF-8" ?>
<SOAP-ENV:Envelope
xmlns:xsi="http://www.w3.org/1999/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/1999/XMLSchema"
xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/">
<SOAP-ENV:Body>
<ns1:Num_Tel_Personne_Response xmlns:ns1="urn:MySoapServices"
SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/">
<return xmlns:ns2="http://schemas.xmlsoap.org/soap/encoding/"
xsi:type="ns2:Array" ns2:arrayType="xsd:string[2]">
<item xsi:type="xsd:string">Alain Debra</item>
<item xsi:type="xsd:string">0607070809</item>
</return>
</ns1: Num_Tel_Personne_Response >
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
Comme on peut le constater, seule la spécification du type contenu dans le tag <return> du message est modifiée (en plus du nom de la fonction invoquée). C'est donc ici une structure de tableau qui est retournée : xsi:type="ns2:Array" ns2:arrayType="xsd:string[2]" à la place de l'entier retourné précédemment.
Bien entendu, pour que cet exemple soit fonctionnel, il serait également nécessaire d'effectuer quelques changements dans le fichier WSDL de description du Web Services sous peine d'obtenir une erreur dû à un mauvais type de donnée retourné, mais cet exemple est néanmoins très parlant pour prouver la simplicité avec laquelle SOAP s'est adapté à ce changement de structure.
Aujourdhui, SOAP, même sil est parfois critiqué à cause de la lourdeur imposée par la verbosité dXML, est devenu un standard incontournable dans le monde des Web Services et un service se doit en principe d'être au moins accessible par ce protocole.
3.3 - WSDL
Afin de pouvoir invoquer un Web Services, il est obligatoire de connaître certaines informations comme par exemple son emplacement, ses méthodes, les paramètres à transmettre, etc. Cest en face à ce besoin que le standard WSDL (Web Service Description Language), basé sur le langage XML, est né.
Le standard WSDL est un langage de description de Web Services qui permet aux applications désirant les utiliser d'auto-configurer leurs échanges. Pour cela, un fichier WDSL contient toutes les informations nécessaires du Web Services pour permettre aux clients d'établir leurs requêtes d'invocation de méthodes. On dit aussi quun fichier WSDL est un "contrat" établi entre les différentes parties.
Les requêtes émises par le client devront être traduites au format XML afin de les rendre compréhensibles par le Web Services. Une fois ces requêtes traitées, ce sera au tour des réponses XML qui en résultent dêtre retraduites dans le langage utilisé par le client. Ce mécanisme de transformation (marshaling / unmarshaling en anglais) est réalisé grâce à un proxy généré dynamiquement pour chacune des requêtes à partir du fichier WSDL. Cest donc grâce à ce mécanisme que les Web Services peuvent être indépendant des langages de programmation et des plateformes sur lesquelles ils sexécutent.
Un fichier WSDL est composé de 8 sections principales :
Ø définitions : élément racine du document, il contient le nom du Web Services et les diverses déclarations despaces de noms utilisés,
Ø types : permet de décrire tous les types de données utilisés dans les messages,
Ø messages : défini le nom de la balise qui contiendra le message. Chaque message peut contenir plusieurs éléments "part" qui permettront de le décomposer,
Ø portTypes : défini les opérations que peut effectuer le Web Services ainsi que les messages (input, output ou fault) qu'il comprend. Dans le monde de l'échange de messages, les points de connexion sont des ports et la définition abstraite d'un port est appelée "type de port",
Ø opérations : les opérations sont les méthodes proposées par le Web Services,
Ø liaison (binding) : permet de décrire la manière dont le Web Services sera implémenté (protocole, format de données des opérations, type de port particulier, ). Les informations spécifiques à SOAP sont décrites dans cette partie,
Ø service : permet de définir les adresses permettant l'invocation du Web Services,
Ø port : cest le point daccroche du Web Services, il est identifié de manière unique par la combinaison d'une adresse internet et d'une liaison,
Ø documentation : contient déventuels commentaires à lintention des développeurs.
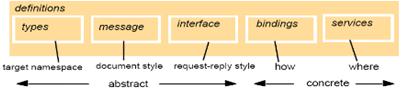
Lannonce de la version 2.0 de WSDL courant 2007 a marqué la fin des travaux par le W3C concernant ce protocole, ce dernier estimant que cette version était maintenant mûre et suffisante pour répondre aux besoins de bases actuels et futurs en matière de Web Services.
Voici un exemple de fichier WSDL complet :
<?xml version="1.0" encoding="UTF-8" ?>
<!-- partie 1 : Définitions -->
<definitions name="monServiceWeb"targetNamespace="urn:monServiceWeb"
xmlns:typens="urn:monServiceWeb"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:soapenc="http://schemas.xmlsoap.org/soap/encoding/"
xmlns:wsdl="http://schemas.xmlsoap.org/wsdl/"
xmlns="http://schemas.xmlsoap.org/wsdl/">
<!-- partie 2 : Types -->
<types>
<xsd:schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="urn:monServiceWeb">
</xsd:schema>
</types>
<!-- partie 3 : Messages -->
<message name="getEnvoiSMSRequest">
<part name="telephone_sms" type="xsd:string" />
<part name="message_sms" type="xsd:string" />
</message>
<message name="getEnvoiSMSResponse">
<part name="sms" type="xsd:string" />
</message>
<!-- partie 4 : Ports Types -->
<portType name="monServiceWebPort">
<!-- partie 5 : Opérations -->
<operation name="getEnvoiSMS">
<input message="typens:getEnvoiSMSRequest"/>
<output message="typens:getEnvoiSMSResponse"/>
</operation>
</portType>
<!-- partie 6 : Binding -->
<binding name="monServiceWebBinding" type="typens:monServiceWebPort">
<soap:binding style="rpc"transport="http://schemas.xmlsoap.org/soap/http"/>
<operation name="getEnvoiSMS">
<soap:operation soapAction="monServiceWebAction"/>
<input name="getEnvoiSMSRequest">
<soap:body use="encoded" namespace="urn:monServiceWeb"
encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"/>
</input>
<output name="getEnvoiSMSResponse">
<soap:body use="literal" />
</output>
</operation>
</binding>
<!-- partie 7 : Services -->
<service name="monServiceWebService">
<documentation> Info : Contact webmaster for more information </documentation>
<!-- partie 8 : Ports -->
<port name="monServiceWebPort"binding="typens:monServiceWebBinding">
<soap:address location="http://x.x.x.x/serveur_sms.php"/>
</port>
</service>
</definitions>
3.4 - UDDI
A partir du moment où un Web Services est créé, une entreprise doit pouvoir le rendre disponible et inversement, les développeurs doivent pouvoir le trouver. La découverte d'un Web Services est une étape essentielle car cest à cette occasion que lon pourra récupérer le contrat WSDL sans lequel rien ne serait possible.
Cest suite à ce besoin que les sociétés Ariba, IBM et Microsoft ont débutées lélaboration du standard UDDI (Universal Description, Discovery and Integration), finalement repris puis défini par l'OASIS (Organization for the Advancement of Structured Information Standards), dans le but de fournir une manière standard de publier et d'interroger les Web Services.
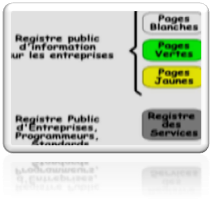
La spécification UDDI adopte une approche basée sur un annuaire virtuel distribué qui permet à un utilisateur, via une interface Web, de publier ou de rechercher un Web Services. UDDI est pour simplifier comparable à un annuaire téléphonique papier traditionnel (en plus complet).
UDDI contient trois types dinformations :
Ø les pages blanches qui identifient les prestataires de Web Services, c'est-à-dire quelles contiennent des informations sur les entreprises (nom, adresse, numéro de téléphone ),
Ø les pages jaunes qui classent les Web Services daprès leur secteur dactivité comme dans les pages jaunes de notre annuaire papier classique,
Ø les pages vertes qui contiennent les informations techniques sur le Web Services lui-même, c'est-à-dire toutes les informations nécessaires à son utilisation (url, interfaçage ).
Il est utile de bien comprendre quUDDI ne fait que classer les Web Services et que lutilisateur, après avoir trouvé le Web Services désiré, devra se débrouiller pour récupérer les informations contenues dans son fichier WSDL pour pouvoir l'utiliser.
Les recherches ou ajouts de Web Services dans l'annuaire se font par requêtes XML (définies dans le schéma fournit par uddi.org) intégrées au sein dune enveloppe SOAP. Ces requêtes peuvent être faites, soit par le Web, soit de manière logicielle, deux API étant prévues à cet effet (Inquiry API et Publication API).
Cinq informations sont importantes pour enregistrer un Web Services :
Ø BusinessEntity : contient toute linformation concernant lentreprise, son secteur dactivité et les éventuels autres Web Services quelle propose, cette partie représente les pages blanches,
Ø BusinessService : contient les descriptions de lensemble des Web Services proposés par lentreprise, cette partie correspond aux pages jaunes,
Ø BindingTemplate : contient les informations techniques concernant le Web Services et ses points daccès, cette partie représente les pages vertes,
Ø tModel : cette partie permet de décrire de façon suffisamment précise les spécifications du Web Services pour connaitre son fonctionnement et le rendre accessible,
Ø PublisherAssertion : cette partie sert surtout aux grandes entreprises pour lesquelles la description BusinessEntity ne suffirait pas pour la décrire de façon assez précise.
Schéma de fonctionnement général
Ø La partie businessEntity décrit lentreprise qui publie le Web Services, elle englobe une ou plusieurs parties businessService.
Ø Chaque partie businessService contient des informations techniques et descriptives sur le Web Services publié. Pour cela, il contient une ou plusieurs sections bindingTemplate.
Ø Chacune des sections bindingTemplate contient à son tour des parties tModel qui vont permettre de présenter les spécifications techniques du Web Services.

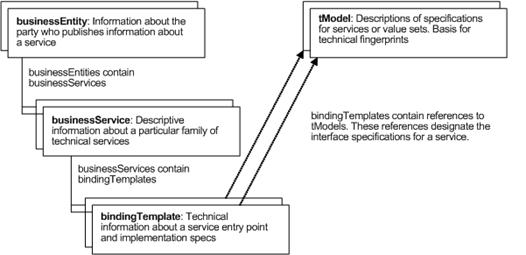
Nous nallons pas entrer plus profondément dans les entrailles dUDDI car il semblerait aujourdhui que lintérêt pour cette technologie décroît sérieusement. La raison est quà lorigine, UDDI a été créé dans le but de devenir un immense annuaire public où chacun pourrait trouver, voir éventuellement acheter, certains Web Services mais à la place de cela, il sest plutôt transformé en un lieu déchange privé uniquement adapté aux grandes entreprises.
En effet, dans la majorité des cas, les Web Services recensés sur UDDI ne sont pas publics et ne sont ouverts quà un groupe restreint de partenaires commerciaux ou même parfois simplement utilisés à des fins de communication interne au sein d'une même entreprise.
Il est donc de plus en plus fréquent que les développeurs contournent purement et simplement UDDI et font en sorte d'obtenir et de séchanger directement les documents WSDL selon les besoins.
Voici un exemple de fichier exploitable par UDDI
<businessEntity businessKey= "A687FG00-56NM-EFT1-3456-098765432124">
<name>Acme Travel Incorporated</name>
<description xml:lang="en"> Acme is a world leader in online travel services </description>
<contacts>
<contact useType="US general">
<personName>Acme Inc.</personName>
<phone>1 800 CALL ACME</phone>
<email useType="">acme@acme-travel.com</email>
<address>
<addressLine>Acme</addressLine>
<addressLine>12 Maple Avenue</addressLine>
<addressLine>Springfield, CT 06785</addressLine>
</address>
</contact>
</contacts>
<businessService serviceKey="uddi:bea.com:servicebus:Domain:Project:JMSMessaging"
businessKey="uddi:9cb77770-57fe-11da-9fac-6cc880409fac" xmlns="urn:uddi-org:api_v3">
<name>JMSMessagingProxy</name>
<bindingTemplates>
<bindingTemplate bindingKey="uddi:4c401620-5ac0-11da-9faf-6cc880409fac"
serviceKey="uddi:bea.com:servicebus:Domain:Project:JMSMessaging">
<accessPoint useType="endPoint">
jms://server.com:7001/weblogic.jms.XAConnectionFactory/ReqQueue
</accessPoint>
<tModelInstanceDetails>
<tModelInstanceInfo tModelKey="uddi:uddi.org:transport:jms">
<instanceDetails>
<instanceParms>
<ALSBInstanceParms xmlns="http://www.bea.com/wli/sb/uddi">
<property name="is-queue" value="true"/>
<property name="request-encoding" value="iso-8859-1"/>
<property name="response-encoding" value="utf-8"/>
<property name="response-required" value="true"/>
<property name="response-URI" value="jms://server.com:7001/
.jms.XAConnectionFactory/RespQueue"/>
<property name="response-message-type" value="Text"/>
<property name="Scheme" value="jms"/>
</ALSBInstanceParms>
</instanceParms>
</instanceDetails
</tModelInstanceInfo>
<tModelInstanceInfo tModelKey="uddi:bea.com:servicebus:protocol:messagingservice">
<instanceDetails>
<instanceParms>
<ALSBInstanceParms xmlns="http://www.bea.com/wli/sb/uddi">
<property name="requestType" value="XML"/>
<property name="RequestSchema" value="http://server.com:7001/
sbresource?SCHEMA%2FDJS%2FOAGProcessPO"/>
<property name="RequestSchemaElement" value="PROCESS_PO_007"/>
<property name="responseType" value="Text"/>
</ALSBInstanceParms>
</instanceParms>
</instanceDetails>
</tModelInstanceInfo>
</tModelInstanceDetails>
</bindingTemplate>
</bindingTemplates>
<categoryBag>
keyedReferenceGroup tModelKey="uddi:bea.com:servicebus:properties">
<keyedReference tModelKey="uddi:bea.com:servicebus:servicetype"
keyName="Service Type" keyValue="Mixed" />
<keyedReference tModelKey="uddi:bea.com:servicebus:instance"
keyName="Service Bus Instance" keyValue="http://cyberfish.bea.com:7001" />
</keyedReferenceGroup>
</categoryBag>
</businessService>
</businessEntity>
3.5 - REST
REST (REpresentational State Transfer) est une approche alternative à SOAP et XML-RPC en matière d'implantation de Web Services qui commence sérieusement à faire parler d'elle car elle parvient de plus en plus à s'imposer face à ces deux compères pourtant aujourdhui reconnus comme étant des piliers en matière de Web Services. Son intérêt est tel, quil est aujourdhui devenu impossible d'en faire limpasse.
REST nest pas un standard ou un protocole reconnu par les organismes de normalisation et ne possède donc aucune reconnaissance dans ce sens. Néanmoins, même si REST n'est pas reconnue comme standard en tant que tel, elle repose néanmoins sur des standards éprouvés qui ont largement fait leurs preuves. REST est donc, à ce jour, plutôt considéré comme étant une "philosophie" de l'utilisation du Web qui repose sur des principes architecturaux déjà existants afin d'en permettre une exploitation optimum.
Cette "philosophie", que nous allons tout de même définir comme étant un style d'architecture à part entière, a été élaborée en 2000 par Roy Fielding en personne (créateur entre autre du protocole HTTP et du serveur Web Apache), car il estimait que dans bien des cas les méthodes HTTP de bases, combinées avec de bonnes URI, étaient largement aussi efficace et surtout beaucoup plus simple que d'utiliser les couches d'abstraction proposées par SOAP et XML-RPC.
Cette réflexion n'est pas apparue par hasard, la raison est quà lorigine, les Web Services devaient reposer sur un protocole ouvert, stable et robuste comme HTTP ou XML mais sans en altérer les performances et la qualité. Malheureusement, avec l'engouement pour les Web Services, SOAP a été contraint de se complexifier (utilisation de SMTP, gestion des pièces jointes, aspects sécurité, ...) et il s'est vu entouré d'une multitude d'autres formats et protocoles comme par exemple WS-Addressing, WS-Security, UDDI, . SOAP est donc devenu pour beaucoup, trop complexe à mettre en uvre dans les situations ne nécessitant pas une complexité accrue.
Le résultat d'une telle bataille entre deux technologies est classique. Il y'a d'un coté les poids lourds de l'industrie (IBM, Microsoft, Oracle, HP,..) qui ont investis des sommes faramineuses dans ces technologies et qui, pour récupérer leurs investissements, doivent les rendre opérationnelles à tout prix, et de l'autre coté un groupe de petits partisans privilégiant la véritable efficacité d'une technologie plutôt que les débats politiques qui en résultent. Dans le camp des partisans, nous retrouvons en particulier ici les prôneurs des méthodes Agiles qui ont totalement délaissés Java et qui ne jurent plus que par Ruby on Rails qui intègre nativement et de façon quasi transparente REST au cur de son architecture.

Roy Fielding à la Rails conférence 2007
Roy Fielding explique dans sa thèse décrivant l'approche REST qu'il existe deux façons daborder un processus de conception darchitecture. La première, qui met en avant la créativité, est de partir de zéro et de construire petit à petit une architecture à base de composants jusqu'à obtenir le système envisagé. La seconde approche, sur laquelle a été défini REST, consiste à répondre tout d'abord aux besoins du système dans son ensemble puis d'y ajouter ensuite les contraintes nécessaires au fur et à mesure suivant les exigences rencontrées.
REST repose donc à la fois sur larchitecture existante du Web et sur les différents standards qui le compose, cela permet de retrouver certains principes simples :
Ø chaque ressource du système est accessible via une URI unique et connaitre cette URI doit être suffisant pour accéder à la ressource,
Ø l'utilisation du protocole HTTP permet de fournir une interface uniforme à chacune des ressources via les fonctions de base du protocole (GET, POST, PUT et DELETE),
Ø l'utilisation des Types MIME pour la description des formats (text/xml, image/gif ),
Ø chaque opération doit être auto-suffisante et autonome, c'est-à-dire qu'il ny a pas de gestion détat et que tous les paramètres sont intégralement transmis à chaque requête,
Ø l'utilisation de standards hypermédias, c'est-à-dire pouvant transporter plusieurs types d'information (texte, image, vidéo...),
Ø l'utilisation de liens entre les ressources afin d'assurer la navigation au sein de lapplication,
Ø la gestion de la sécurité se fait selon les normes usuelles (SSL, sessions, cookies...) et est principalement assurée par les navigateurs,
Ø la possibilité dutiliser ou non les mécanismes de cache standard (serveur Web, proxy, passerelle, navigateurs ).
Il est important de bien différencier HTTP et REST car on pourrait avoir tendance à penser que REST n'est en réalité qu'une description du protocole HTTP. Cette ressemblance est présente car HTTP est à la base de la quasi-totalité des applications Web existantes et que REST repose lui-même sur cette infrastructure, c'est-à-dire principalement sur HTTP. La différence est que REST ne se limite pas à HTTP et en contrepartie, il est tout à fait possible de faire une application HTTP sans respecter la philosophie REST. En fait HTTP est simplement une fonctionnalité utilisé par REST.
![]()
Dans lapproche REST, tout ce qui peut être nommé (compte utilisateur, article de journal, tableau de bord, document, image, service ) est considéré comme étant une ressource et se voit attribuer une URI unique de manière à pouvoir interagir avec elle. REST utilisera pour cela les méthodes de base du protocole HTTP qui sont POST, GET, PUT et DELETE.
Chaque opération d'un Web Services est donc associée à une URI et l'on pourra y accéder via les méthodes HTTP classiques. Le contenu des messages sera lui, simplement encodé en XML et la distinction entre les en-têtes et le contenu de ce dernier sera laissée à la charge des applications. Il est à noter que l'encodage en XML, bien que privilégié, n'est toutefois pas obligatoire et des réponses par exemple au format JSON (JavaScript Object Notation) ou en objets Java sérialisés sont également acceptables.
Dans REST, chaque ressource, identifiée par une URI unique, doit obligatoirement fournir une interface d'accès uniforme constituée d'un ensemble :
Ø de Types MIME permettant de décrire le format des paramètres envoyés et des réponses attendues.
Ø d'opérations correspondant aux verbes (méthodes) HTTP (POST, DELETE, GET, PUT), ces verbes correspondront aux méthodes dites "CRUD" (Create, Read, Update, Delete).
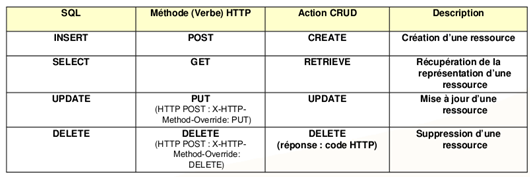
Pour effectuer une comparaison, là où SOAP et XML-RPC se basent sur des méthodes, REST se base sur les ressources existantes. Avec REST, connaître lURI dune ressource suffit pour y accéder et interagir avec elle.

Roy Fielding précise, toujours dans sa thèse, les avantages de ce style architectural par rapport aux autres styles d'architectures d'applications Web :
Ø l'application est plus simple à entretenir car les liens sont mieux structurés, car de façon universelle,
Ø l'absence d'état sur le serveur :
· conduit à une consommation de mémoire inférieure et permet par conséquent au serveur de répondre à un plus grand nombre de requêtes simultanément,
· rend le fonctionnement plus simple à appréhender,
· permet une répartition des requêtes sur plusieurs serveurs avec une meilleure granularité et de manière plus souple,
· permet une meilleure tolérance aux pannes d'un des serveurs,
Ø le respect de la philosophie du protocole HTTP conduit à une architecture plus cohérente et plus simple,
Ø l'utilisation d'URI pour représenter une ressource permet l'utilisation de serveurs caches.
La principale limitation que connait actuellement REST vient de la non standardisation des méthodes PUT et DELETE du protocole HTTP au sein des navigateurs. C'est l'un des freins majeurs à son adoption car même si la possibilité de mettre en place une architecture REST côté serveur, grâce, par exemple à l'utilisation de champs cachés dans les formulaires HTML pour envoyer ces méthodes (comme le fait d'ailleurs le Framework Ruby on Rails), cela demande tout de même des connaissances informatiques non négligeables. Il est également utile de préciser que REST est uniquement une méthode alternative à XML-RPC ou SOAP et un Web Services REST devra également, en principe, être associé à un fichier WSDL pour assurer sa description.
Etudions pour finir un petit exemple d'utilisation de REST
Prenons une entreprise spécialisée dans la vente de fleurs sur Internet qui veut permettre à ses clients d'obtenir, via un Web Services utilisant REST, la liste des articles en vente et éventuellement d'obtenir des informations complémentaires sur un article précis. La liste des articles sera alors disponible à l'URL suivante : http://www.maboutique.com/articles/.
La manière dont le Web Services va générer cette liste n'est pas important pour le client et la seule chose qui va l'intéresser est que cette adresse lui fournira la liste des articles de la boutique. Cette étape montre déjà un point très positif de REST car nous constatons que lentreprise est libre dimplémenter la création de sa liste de la manière dont elle le souhaite sans impacter les visiteurs, c'est le principe du "couplage lâche" (loose coupling).
Le client recevra la liste sous la forme suivante :
<?xml version="1.0"?>
<p:Articles xmlns:p=http://www.maboutique.com/ xmlns:xlink="http://www.w3.org/1999/xlink">
<Article id="0001" xlink:href="http://www.maboutique.com/Articles/0001"/>
<Article id="0002" xlink:href="http://www.maboutique.com/Articles/0002"/>
...
</p: Articles >
Cette liste contient des liens permettant d'obtenir des informations détaillées sur chaque article et en cliquant sur le lien http://www.maboutique.com/Articles/0001/ nous arrivons alors sur la fiche de présentation de l'article 0001 qui, dans cet exemple, permettra d'obtenir un descriptif encore plus détaillé en cliquent sur le lien http://www.maboutique.com/Articles/00001/details.
La réponse renvoyée au client sera alors :
<?xml version="1.0"?>
<p:Articles xmlns:p=http://www.maboutique.com/ xmlns:xlink="http://www.w3.org/1999/xlink"> <Article-ID>0001</Article-ID>
<Nom>Fleur : tulipe</Nom>
<Description>Jaune et noir</Description>
<Details xlink:href="http://www.maboutique.com/Articles/0001/details"/>
<Prix="EUR">1,50</Prix>
<Enstock>1500</Enstock>
</p: Article>
Nous voyons ici la véritable force de REST : les liens entre les ressources.
REST est en train de gagner de plus de points dans l'opinion des développeurs
et pour preuve, les API des gros Web Services comme Amazon, Yahoo! et eBay
qui offraient un accès à la fois avec SOAP et REST ont abandonné SOAP et ne
proposent aujourd'hui plus qu'un accès via REST pour certaines de leurs
fonctionnalités.
IV - Les WS - *
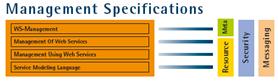
Nous venons de voir les technologies (XML-RPC, SOAP, WSDL, UDDI et REST) qui composent aujourd'hui larchitecture de référence des Web Services. Cependant, cette architecture montre rapidement ses limites dès que les exigences vont au delà dinteractions simples via des protocoles standards et l'ajout de nouveaux standards, pour les compléter, s'est vite fait sentir pour pouvoir répondre aux exigences demandées. Le but ne fut alors pas de jeter tout ce qui avait été réalisé jusqu'ici dans le domaine, mais plutôt, du fait de son architecture en couche, de venir y greffer des protocoles complémentaires. C'est pour répondre à ce besoin que le groupe architecture du W3C s'est activement penché à lélaboration dune architecture étendue dans laquelle plusieurs couches, répondant chacune à un standard et un besoin particulier des Web Services, viendront se greffer sur les couches de bases. L'ensemble de ces couches a alors pris la dénomination de WS - *.
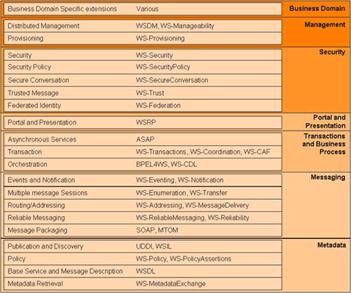
Architecture étendue proposé par le W3C pour les Web Services
4.1 - La WS - I
Afin dassurer linteropérabilité entre les implémentations de toutes ces nouvelles normes, une organisation, baptisée WS-I, a été fondée le 6 février 2002 sous l'impulsion de Microsoft, d'IBM et de BEA Systems. Le consortium WS-I regroupe aujourd'hui plus de 160 sociétés et son objectif est de faire progresser linteropérabilité des Web Services en définissant les bonnes pratiques d'utilisation de standards existants et à venir.
Les travaux du WS-I sont menés en coopération avec les organismes de standardisation OASIS et W3C. Le WS-I a ainsi élaboré et proposé trois types de livrables :

Ø des profils regroupant des règles de bonnes utilisations des standards en vue dassurer linteropérabilité des implémentations,
Ø des exemples mettant en uvre ces profils,
Ø des outils de tests permettant de comparer une implémentation avec un profil.
Ø Les profils
Les profils sont donc des règles de bonne utilisation destinées à permettre une bonne interopérabilité des Web Services. Voici comment sarticulent les différents profils :
· le Basic Profile constitue le socle des profils,
· le Basic Security Profile y ajoute une dimension sécurité.
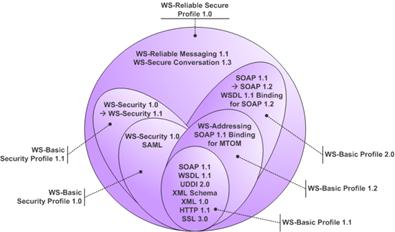
Il est intéressant de noter que la sortie du Basic Profile 1.0, première version officielle, a déjà permis de résoudre plus de 200 problèmes d'interopérabilité. Au jour de la rédaction de ce chapitre c'est la version Basic Profile 1.2 qui est en cours de finalisation. Lobjectif à terme sera de regrouper lensemble des profils au sein dun Reliable Security Profile 1.0.
Ø Les outils
Le WS-I propose deux outils de tests de conformité : Le Monitor et lAnalyzer.
- Le Monitor est configuré pour intercepter les requêtes et les réponses échangées entre un client et un Web Services.
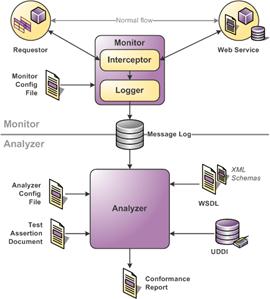 LAnalyzer
permet lui de tester la conformité par rapport à un profil. L'analyse effectuée
peut porter par exemple, sur la définition du contrat WSDL, le
contenu dun annuaire UDDI ou encore les traces générées par le monitor.
LAnalyzer
permet lui de tester la conformité par rapport à un profil. L'analyse effectuée
peut porter par exemple, sur la définition du contrat WSDL, le
contenu dun annuaire UDDI ou encore les traces générées par le monitor.
4.2 - La carte des WS - * aujourd'hui
Nous n'allons pas détailler les protocoles composants aujourd'hui les WS-* car leur présentation serait le sujet d'un mémoire à part entière mais voici tout de même la carte des avancées réalisées afin de bien se rendre compte du travail titanesque qui est en train de s'effectuer dans ce domaine. A l'heure actuelle, ces travaux sont réalisés conjointement par le WS-I, le W3C, l'IETF et l'OASIS et la plupart des protocoles sont encore en cours de développement
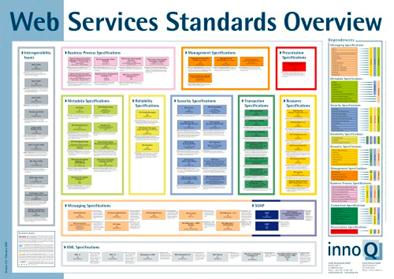
L'architecture actuelle des WS - *
Avec comme dépendances principales :