

LE WEB SEMANTIQUE
![]()
Le World Wide Web, dans son état actuel, est comparable à une géographie qui utiliserait de mauvaises cartes. Pour améliorer cette cartographie, il est nécessaire de disposer, en plus des informations lisibles par les humains, de descriptions de contenu interprétables par des machines. Ce sera l'objet de cette partie du mémoire.
I - La sémantique
Pour bien comprendre cette partie, il faut sintéresser à deux concepts de linguistique qui sont mis en opposition la syntaxe et la sémantique. Pour simplifier l'explication de ces termes, nous pourrions dire que la syntaxe porte sur la forme des phrases, cest-à-dire les caractères et les mots employés, tandis que la sémantique concerne le fond, c'est-à-dire le sens des phrases. Ainsi les deux phrases suivantes ont deux syntaxes différentes mais une seule et même sémantique :
Ø chef dÉtat américain,
Ø président des États-Unis dAmérique.
La sémantique est donc l'étude scientifique de la signification. Sa complexité s'explique par le fait qu'elle met en jeu plusieurs niveaux de données qui débutent avec le sens des mots, puis des phrases, puis des relations sémantiques entre les phrases dans le discours pour s'étendre jusqu'aux relations pragmatiques, c'est-à-dire les éléments du langage dont la signification ne peut être comprise qu'en connaissant le contexte.
Pour être efficace, la sémantique exige donc l'utilisation de techniques, d'outils et de méthodes spécifiques. Elle doit également tenir compte de la langue et de la culture des peuples étudiés car une description véridique dans un pays peut être totalement infondée dans le pays voisin.
1.1 - Le niveau métalinguistique
Quand on parle de l'aspect linguistique, on pense immédiatement à la discussion entre personnes, que ce soit simplement pour s'exprimer ou alors pour changer une situation en cours. Toutefois, la langue ne sert pas qu'à cela car elle est également utilisée, bien souvent sans que l'on ne s'en aperçoive, pour expliquer et décrire, la langue elle-même.
Cette partie de la langue destinée à en décrire une autre partie s'appelle l'emploi métalinguistique et l'ensemble des mots nécessaires à la réalisation de cette description prend le terme de métalangage. On utilise un métalangage dans la majorité des phrases que nous prononçons dans notre vie quotidienne comme l'illustrent les deux phrases suivantes :
Ø la table est verte (verte = métalangage pour décrire la table),
Ø elle peut courir vite (vite = métalangage pour décrire sa façon de courir).
1.2 - Les relations sémantiques
Toutes les relations que nous allons maintenant détailler sont destinées à présenter les liens pouvant exister entre différents termes linguistiques. Cette démonstration d'existence de relations permettra d'établir des conclusions lors de la construction, comme nous le verrons ultérieurement, des ontologies ou des vocabulaires nécessaires à l'intégration de la sémantique au sein des systèmes d'information et plus particulièrement des applications Web.
Ø Homonymie et polysémie
L'étude des sens est compliquée du fait de la complexité du langage humain lui-même où plusieurs formes a priori distinctes peuvent néanmoins entretenir certaines relations :
Ø la construction du palais / une construction magnifique,
Ø un livre pour enfants / une livre de beurre.
Dans le premier exemple, il existe une relation de sens entre les deux occurrences "construction", le premier sens désignant une action et le deuxième le résultat de cette action. Pour démontrer l'existence d'une telle relation entre deux occurrences, on admet qu'une forte certitude suffit. Cette intuition sera alors formalisée sous le terme polysémie.
Dans le second exemple, bien qu'il n'existe aucune relation de sens entre les deux occurrences, ces deux termes peuvent tout de même être mis en relation du fait de leurs formes et prononciations identiques. Ces deux termes sont alors désignés sous la relation d'homonymie. Si par contre, toujours sans aucune relation de sens, ces deux termes avaient eu une orthographe différente mais une prononciation identique, nous aurions alors parlé d'homophonie. Si, pour finir, ils avaient eu la même orthographe mais une prononciation différente, nous aurions utilisé le terme homographie.
La relation que nous allons voir maintenant est très intéressante car elle permet d'établir des affirmations pour certains termes en se basant sur la description d'autres termes :
Ø si c'est une carotte, cela implique que ce soit un légume,
Ø si c'est une tomate, cela implique que soit un légume,
Ø si c'est un légume, cela n'implique pas nécessairement que ce soit une tomate,
Ø si c'est une carotte, cela implique que ce ne soit pas une tomate.
On constate ici que tomate et carotte ont une relation spéciale avec légume. On dit alors que légume est l'hyperonyme de tomate et de carotte, et que tomate et carotte sont des hyponymes de légume. La relation entre un hyponyme et un hyperonyme s'appelle l'hyponymie. Entre tomate et carotte, il n'y a aucune implication mais comme les deux termes partagent le même hyperonyme, on dit que ce sont des co-hyponymes. L'existence des relations d'hyponymie donne la possibilité de définir plusieurs niveaux d'abstraction et l'on peut ainsi représenter les relations d'hyponymie au moyen d'un arbre.
légume
|
-------------------
| |
tomate carotte
La synonymie est sans doute la relation sémantique la plus connue. Pour réussir à prouver une synonymie, on utilise l'implication mutuelle, c'est-à-dire le fait que l'un des termes implique l'autre, et que le deuxième terme implique le premier :
Ø ceci est un soulier ==> ceci est une chaussure,
Ø ceci est une chaussure ==> ceci est un soulier.
Il faut donc manipuler cette technique avec précaution car le mot "doux" par exemple est synonyme à la fois de "mou" et de "gentil", ce qui ne relève pas du tout de la même signification.
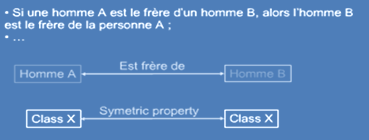
Deux items lexicaux sont en relation d'antonymie si on peut exhiber une symétrie de leurs traits sémantiques par rapport à un axe. L'antonymie désigne un phénomène assez vaste :
Ø ce numéro est pair ==> ce numéro n'est pas impair,
Ø ce numéro n'est pas pair ==> ce numéro est impair,
Ø ce numéro est plus pair que l'autre ==> impossible.
On voit ici qu'il n'existe aucune relation d'implication entre les termes de gauche et les termes de droite. Par contre, il existe bien une relation entre ces termes car la négation de l'un implique obligatoirement l'affirmation de l'autre. Nous voyons dans la dernière phrase qu'un antonyme n'accepte pas la gradation, c'est-à-dire qu'il ne peut pas être qualifié par "plus" ou "moins".
Ce type de relation concerne la dépendance ou l'appartenance entre deux termes :
Ø il m'a touché le doigt,
Ø il m'a touché la main.
Ici, la première phrase implique forcément la deuxième et linguistiquement parlant, le doigt a une relation spéciale avec la main. Cette relation est appelée méronymie et signifie que le premier terme est vu comme étant une partie intégrante du second.
Ø Les relations sérielles et cycliques
Deux autres types de relations existantes en sémantique résident dans l'étude des groupes de termes, dont voici deux exemples :
Ø un deux trois quatre cinq six ...,
Ø lundi mardi mercredi jeudi vendredi samedi dimanche.
Le premier exemple nous présente une relation de série où chaque membre se définit par rapport à la place occupée par son prédécesseur ou son successeur. L'exemple suivant nous présente lui la relation de cycle qui permet de représenter un groupe de termes pouvant se reproduire indéfiniment.
Ø Présupposition et implication
Les deux derniers types de relations que nous allons voir sont basées sur notre expérience et sur l'ensemble de nos connaissances. Prenons l'exemple suivant :
Ø Max a perdu ses clés.
Cet énoncé pose que Max a perdu ses clés, mais il permet également d'émettre une relation de présupposition qui donnera la possibilité d'énoncer une vérité concernant une chose, sans que la chose soit dite :
Ø Max existe,
Ø Max avait des clés avant de les perdre.
La relation inverse, où la vérité d'un énoncé peut garantir la présupposition d'une chose qui n'est pas dite, sera elle appelée relation d'implication.
II - La sémantique appliquée au Web
Le World Wide Web, aussi appelé Web syntaxique, a été conçu à l'origine pour la compréhension humaine et bien que les informations qui le constituent soient lisibles par des machines, ces dernières sont pour l'instant incapables de les comprendre.
Pour le vérifier, nous allons prendre le moteur de recherche Google, qui est l'un des moteurs de recherche le plus efficace actuellement, pour y effectuer une recherche afin de connaître par exemple le nombre d'habitant de la capitale de la Suisse. Nous indiquons donc les mots-clés "nombre habitant capitale suisse" et obtenons le résultat suivant :
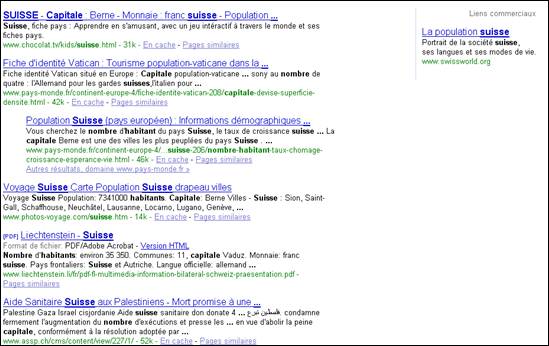
Nous voyons que le premier et le troisième résultats peuvent éventuellement être assez proches de ce que nous recherchons, mais pour ce qui est des résultats suivants, entre la fiche du Vatican, les photos souvenirs d'un voyage et une association d'aide aux Palestiniens, il n'y a pas grand-chose pouvant correspondre à notre recherche. Pourtant la question posée est très simple et malgré cela, Google, bien qu'il soit le meilleur au monde, n'a pas été capable de me fournir un résultat concluant.
La raison est simple, un moteur de recherche classique ne connait pas la signification des mots-clés, il se contentera d'effectuer sa recherche en vérifiant la présence de vos mots-clés dans les pages Web qu'il aura indexé et il vous retournera comme résultat toutes les pages où une correspondance aura été trouvée. Le principe n'est pas mauvais mais le problème est que le moteur de recherche, en plus de ne pas comprendre les mots, ne tiendra également pas compte de l'ordre dans lequel vos mots-clés vont être présents dans la page. Cela veut donc dire que pour lui, le résultat sera considéré comme correct même si le premier mot-clé est en début de page et le second en fin de page, ce qui fait qu'en réalité, ils n'ont plus aucun lien avec votre recherche. Il est évident que les moteurs de recherche tiennent compte d'une multitude d'autres détails complexes pour établir leurs recherches comme par exemple la notoriété des pages, mais le principe de base reste néanmoins identique à ce que nous venons de voir.
Le principe du Web sémantique va donc être de réussir, comme son nom le laisse supposer, à appliquer les principes de la sémantique au Web lui-même. La différence est que cette fois la sémantique ne va plus être appliquée pour améliorer la compréhension humaine mais pour permettre la compréhension des données directement par des machines. La sémantique devrait donc permettre aux applications, notamment aux Web Services, d'effectuer eux-mêmes certains raisonnements nécessitant jusque là une intervention humaine. La sémantique devrait donc apporter au Web une certaine forme d'intelligence.
Il ne faut néanmoins pas se faire de fausses idées, car le but du Web sémantique ne va pas être de rendre le langage humain compréhensible par les ordinateurs ou de mettre en place une intelligence artificielle qui permettrait au Web de réfléchir. Le principe du Web sémantique est simplement de regrouper l'information de manière intelligente, à l'image d'une gigantesque base de données, où tout est décrit de façon structurée. Le but du Web sémantique va donc être de réussir à transformer cette masse ingérable de pages Web en un gigantesque index hiérarchisé.
Le Web sémantique ne remet par contre aucunement le Web original en cause. Il est au contraire présenté comme étant une extension optionnelle du Web qui reposera sur l'infrastructure déjà existante et sur laquelle on greffera simplement les protocoles nécessaires à la description des données, c'est-à-dire des protocoles permettant l'élaboration d'ontologies et de métadonnées. Le Web sémantique ne modifiera donc en rien l'aspect graphique et un site Web sémantique sera visuellement identique à un site Web classique.
La notion de métadonnées utilisables par les machines fut énoncée pour la première fois en 1994 par l'inventeur du Web lui-même lors de la conférence WWW 94 où fut également annoncée la création du W3C. Ces métadonnées ont alors été présentées comme des représentations de l'information contenue dans les documents et directement utilisables par les machines. Il fallut ensuite attendre 2001 pour voir le W3C lancer officiellement un groupe de travail concernant le Web sémantique.
Au commencement, ce groupe de travail a considéré le Web sémantique comme un moyen d'attacher aux contenus Web des métadonnées en vue d'automatiser certaines tâches applicatives comme par exemple la syndication. Leur projet a donc débuté avec la mise au point des premières métadonnées, baptisées alors RDF, et des premiers schémas XML permettant de décrire les vocabulaires qu'elles vont utiliser. Parallèlement, le groupe a également élaboré une ontologie de profils permettant de regrouper les métadonnées par catégorie et ainsi définir les contextes dans lesquels seront utilisés les contenus.
 |
La structure de RDF, du fait de son extrême généricité, a survécu et sert aujourd'hui de base aux nombreux schémas ou vocabulaires du Web sémantique. Une partie de ces vocabulaires a été spécifiée par le W3C, comme par exemple les langages d'ontologie RDFS et OWL ou le langage de description de thésaurus SKOS. D'autres vocabulaires RDF, sans être spécifiés par le W3C, sont également largement utilisés et constituent des standards de fait dans la communauté du Web sémantique, comme par exemple le vocabulaire FOAF destiné à la description des personnes et des relations qui les lient. De nombreux langages de requête destinés à interroger les graphes RDF ont également vu le jour, mais celui destiné à devenir un standard est SPARQL.
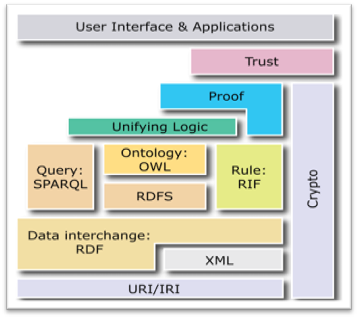
La Layer Cake du W3C concernant le Web sémantique
Les travaux actuels sur le Web sémantique portent essentiellement sur deux aspects : la constitution d'ontologies et l'annotation de documents Web avec une structure sémantique. La première solution aura l'avantage de permettre une description très complexe et précise mais demandera par contre un travail de réflexion très important tandis que la seconde solution aura l'avantage d'être plus simple et rapide mais avec l'inconvénient de devenir très vite limitée lors de travaux complexes. Un point privilégiant tout de même les ontologies est que le Web sémantique, au contraire des systèmes traditionnels de partage de données, qui imposent la même définition des concepts, permet grâce à sa flexibilité d'obtenir des inférences identiques à partir de données différentes. Cette particularité est d'autant plus importante lorsque l'on prend en compte le fait qu'il est possible d'utiliser plusieurs ontologies différentes au sein d'un même document.
Ainsi, nous pourrions dire pour un premier bilan que le Web sémantique ne s'intéresse pas directement au texte en lui-même, mais aux données qui le décrivent, ce qu'on appelle communément les métadonnées, et dont le but sera de donner aux informations un sens que les ordinateurs arriveront à "comprendre".
 |
 2.1 - La base de tout : RDF
2.1 - La base de tout : RDF
RDF (Resource Description Framework) a été développé par le W3C pour définir, structurer et indexer efficacement les ressources Web et leurs métadonnées dans le but, non pas d'en permettre le stockage comme l'on aurait tendance à le penser, mais pour en permettre l'échange. RDF est simplement une structure de données constituée de nuds et organisée en forme de graphe.
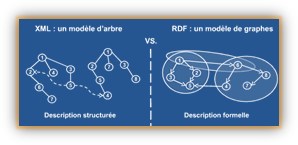
Le principe de RDF réside dans le fait qu'il permet de quasiment tout décrire selon un mécanisme particulièrement simple de phrases minimales composées uniquement d'un sujet, d'un verbe et d'un complément, comme par exemple la phrase "Jean aime la campagne". Dans RDF on parlera alors de déclaration pour désigner le triplet {sujet, verbe, complément} dont les termes techniques deviendront respectivement {sujet, prédicat, objet} avec :
Ø le sujet représentant la ressource à décrire,
Ø le prédicat représentant un type de propriété applicable à cette ressource,
Ø l'objet représentant une donnée ou une autre ressource, c'est la valeur du prédicat.

La phrase "Alain est le créateur de la ressource http://www.monsite.org/texte2" donnera donc comme triplet (attention a bien identifier le sujet car ici on s'intéresse à la ressource et il faut prendre la phrase dans le sens "la ressource a été créé par Alain") :
|
Sujet |
http://www.monsite.org/texte2 |
|
Prédicat |
Créateur |
|
Objet |
Alain |
On remarquera d'embler la ressemblance avec le langage humain. Toutefois, contrairement à certaines phrases du langage humain où l'une des parties du triplet pourrait être omise car sous-entendue comme par exemple dans "Il mange", en RDF les trois éléments sont obligatoires et ici, il faudrait obligatoirement préciser ce qu'il mange "Il mange une banane".
Le sujet et lobjet dune déclaration peuvent être soit une autre déclaration RDF (spécifiée alors par une URI) soit un littéral, c'est-à-dire une chaîne de caractères. Ils peuvent également être définis en tant que nud anonyme pour attacher par exemple des propriétés à la ressource. Le prédicat, quant à lui, sera obligatoirement identifié par une URI.
Voici une image montrant que tout peut être transcrit sous forme d'URI :
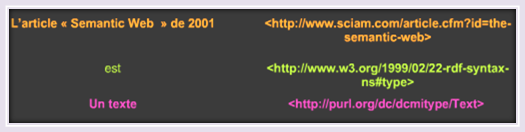
Voici maintenant un exemple destiné à illustrer la notion de nud anonyme :
"Marc a un ami né un 17 mai" peut se traduire par les deux triplets suivants qui utilisent des propriétés définies par le vocabulaire FOAF spécialement conçu pour la description de personne.
ex:Marc foaf:knows _:p1
_:p1 foaf:birthDate 05-17
Le premier triplet se lit "Marc connait p1" et le second "p1 est né un 17 mai". Dans cet exemple "ex:Marc" est une ressource nommée, c'est-à-dire qu'elle est identifiée par une URI. Cette URI sera obtenue en remplaçant le préfixe "ex:" par l'espace de noms XML correspondant.
L'expression "_:p1" représente donc ici l'ami de Marc, une personne anonyme non identifiée par une URI. On peut néanmoins déduire que "_:p1" est de type foaf:Person d'après le premier triplet car la propriété "foaf:knows => rdfs:range => foaf:Person" du langage FOAF impose que foaf:knows soit utilisé pour une personne.
Les syntaxes possibles en RDF
Bien que la version XML de RDF proposée par le W3C, baptisée RDF / XML, soit la version majoritairement utilisée, rien n'oblige les développeurs à l'utiliser car RDF n'est pas un dialecte XML. Voici trois formes possibles de syntaxes RDF :
Ø Du RDF en tant que langage parlé
<Marc> <est> <un homme>.
Cette version présente l'avantage de faciliter la prise en main du modèle, mais, n'étant pas standardisée, elle ne permet pas d'échanges informatiques. Cela reste néanmoins une description RDF valide et elle est principalement utilisée dans les brouillons préparatoires.
Ø La syntaxe RDF/XML
<?xml
version="1.0" encoding="iso-8859-1"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description about="http://websemantique.org/Marc">
<rdf:type resource="http://description.org/schema/animaux/Homme"/>
</rdf:Description>
</rdf:RDF>
Cette solution, certes plus difficile à lire, présente l'avantage d'être en XML et donc de profiter des avantages de ce dernier, notamment en matière d'interopérabilité et de profusion d'outils.
Ø La syntaxe N3 (N-triples, Turtle)
# Base was: file:/Users/karl/Documents/2004/01/20/toto.rdf
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
<http://websemantique.org/Marc> .
a
<http://description.org/schema/animaux/Homme> .
#ENDS
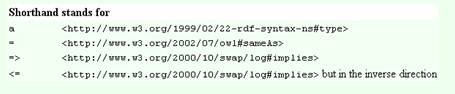
La syntaxe N3 offre l'avantage d'être plus facile à lire et à écrire que la syntaxe XML. Elle convient bien pour l'écriture à la main, des outils traduiront ensuite cette syntaxe en XML. Dans cet exemple, le "a" veut dire type, ce qui donne au final : Marc a pour type homme.
Voici d'autres raccourcis pour la syntaxe N3 :
RDF, même s'il ne se limite pas à ce domaine, est le langage de base du Web sémantique et tous les autres langages du domaine sont constitués d'une base de RDF sur laquelle diverses couches sont venues se greffer. En réalité, RDF n'est pas véritablement considéré comme étant un langage car il n'a pas de syntaxe unique, il est plutôt vu en tant que modèle abstrait comme l'est l'arithmétique par exemple.

2.2 - La construction de vocabulaires pour RDF
2.2.1 - Construction de vocabulaires simples : RDFS
RDFS (RDF Schema) est une version améliorée de RDF. Il contient le nombre minimum de notions et de propriétés nécessaires pour offrir à RDF les moyens de définir des vocabulaires (ou schémas) simples de métadonnées. La première version de RDFS a été proposée en mars 1999 et la recommandation finale a été publiée par le W3C en février 2004.
Un schéma est une collection de classes utilisables au sein du document RDF. Le mécanisme de classe apporté par RDFS est comparable à celui que nous trouvons dans les environnements actuels de programmation orienté objet, c'est-à-dire un système hiérarchique permettant l'héritage. De cette façon, un schéma déjà existant pourra être réutilisé et spécialisé. Pour pouvoir les utiliser, il suffira de les déclarer dans le document RDF à la manière des espaces de noms XML.
Les schémas peuvent être écrits eux-mêmes en RDF et plusieurs schémas différents sont utilisables au sein d'un même document RDF, cela permet aux données d'être basées sur des schémas multiples. Cette propriété est très importante car c'est elle qui va donner la possibilité d'effectuer les traitements sémantiques nécessaires comme par exemple la comparaison entre des données portant des appellations différentes ou encore l'établissement de relations entre différents termes.
Voici un exemple de description RDFS utilisant le schéma FOAF pour décrire l'album "Are You Experienced?" de "Jimi Hendrix" :
<rdf:RDF
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://musicbrainz.org/mm-2.1/album/6b050dcf-
7ab1-456d-9e1b-c3c41c18eed2">
<dc:title>Are You Experienced?</dc:title>
<foaf:maker>
<foaf:Agent rdf:about="http://musicbrainz.org/mm-2.1/artist/33b3c323-
77c2-417c-a5b4-af7e6a111cc9">
<foaf:name> Jimi Hendrix </foaf:name>
</foaf:Agent>
</foaf:maker>
</rdf:Description>
</rdf:RDF>
Toujours grâce aux propriétés des schémas, RDFS va également pouvoir être utilisé pour émettre des restrictions et mettre en place une cohérence des données. Par exemple, pour restreindre le domaine de valeurs d'une propriété, nous pourrons nous servir de la propriété rdfs:range de RDFS. Donc, pour indiquer que les valeurs prises par le type Personne (Person) ne peuvent être que de type chaînes de caractères, il faudra écrire la déclaration suivante :
<rdf:property rdf:about=http://purl.org/dc/elements/1.1/creator>
<rdfs:range rdf:resource=http://www.schema.org/TR/rdf-schema#Person>
<rdfs:range rdf:resource=http://www.w3.org/2000/01/rdf-schema#Literal">
</rdf:property>
Tant que les schémas à réaliser restent assez simples, RDFS sera suffisant mais s'ils atteignent un degré de complexité plus important, ils prendront alors le terme d'ontologies et il sera obligatoire d'utiliser un vocabulaire mieux adapté comme OWL (qui intègre d'ailleurs les principaux composants de RDFS).

Aujourd'hui, on ne fait plus véritablement la différence entre un document purement RDF et un document RDFS, la raison est qu'il devient très rare de trouver un document RDF qui n'utilise pas de schémas. L'appellation RDF(S) est donc maintenant couramment utilisée pour désigner un document, qu'ils soient RDF ou RDFS.
2.2.2 - Construction d'ontologie: OWL
2.2.2.1 - Définition de l'ontologie
En philosophie, l'ontologie est l'étude de l'être en tant qu'être, c'est-à-dire l'étude des propriétés générales de ce qui existe. Par analogie, le terme est repris en informatique et en science de l'information où une ontologie est l'ensemble structuré des termes et concepts représentant le sens d'un champ d'informations, que ce soit par les métadonnées d'un espace de noms ou avec les éléments d'un domaine de connaissances. L'ontologie constitue donc en soi un modèle de données représentatif d'un ensemble de concepts d'un domaine et des relations existantes entre ces concepts.
Voici une définition de l'ontologie mis au point par un groupe de chercheurs français car, à leurs yeux, aucune définition vraiment exacte n'existait dans notre langue française.

Les concepts sont organisés dans un graphe dont les relations peuvent être soit des relations sémantiques, soit des relations hiérarchiques.
L'objectif premier d'une ontologie est de réussir à modéliser l'ensemble des connaissances du domaine donné, et ceci qu'il soit réel ou imaginaire.
Les ontologies décrivent généralement :
Ø individus: les objets de base,
Ø classes: ensembles, collections ou types d'objets,
Ø attributs : propriétés, fonctionnalités, caractéristiques ou paramètres pouvant être posséder et partager par les objets,
Ø relations: liens que les objets peuvent avoir entre eux,
Ø évènements: changements subis par des attributs ou des relations.
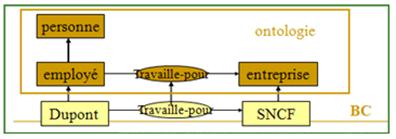
Il est important de fixer la limite entre une ontologie et une base de connaissance. L'ontologie s'arrête à la définition des classes et à partir du moment où l'on spécialise ces classes, on entre alors dans le domaine de la base de connaissance :
Dans le cadre de ses travaux sur le Web sémantique, le W3C a mis en place en 2002 un groupe de travail dédié au développement de langages standards pour modéliser des ontologies utilisables et échangeables sur le Web. S'inspirant de langages déjà existants comme DAML (DARPA Agent Markup Language) et OIL (Ontology Interchange Language) ainsi que des fondements théoriques des logiques de description, ce groupe a publié en 2004 une recommandation définissant le langage OWL (Web Ontology Language), fondé sur le standard RDF et spécifiant une syntaxe XML. Plus expressif que son prédécesseur RDFS, OWL a rapidement pris une place prépondérante dans le paysage des ontologies et est désormais devenu le standard le plus utilisé dans ce domaine.
2.2.2.2 - Le langage OWL
Le langage OWL (Web Ontology Language) permet de définir et instancier des ontologies Web, c'est-à-dire qu'il devrait en principe permettre de décrire tous les types d'entités existantes dans le monde et la façon dont elles sont reliées. Une ontologie OWL va donc contenir des descriptions de classes, de propriétés, d'instances et va être capable de mettre en place des raisonnements découlant de la sémantique et cela à partir d'un ou plusieurs documents.

Il existe trois versions du langage OWL :
Ø OWL Lite : concerne les utilisateurs ayant principalement besoin d'une hiérarchie de classifications et de mécanismes de contraintes simples,
Ø OWL DL : concerne les utilisateurs souhaitant une expressivité maximum sans sacrifier la complétude de calcul (toutes les inférences sont sûres d'être prises en compte) et la décidabilité (tous les calculs seront terminés dans un intervalle de temps fini) des systèmes de raisonnement,
Ø OWL Full : est destiné aux utilisateurs souhaitant une expressivité maximum et la liberté syntaxique de RDF sans garantie de calcul.
OWL étend les possibilités du langage RDFS avec notamment la gestion de relations d'équivalences entre classes et de différences entre ressources, de classes énumératives, de cardinalités, d'une typographie plus riche des propriétés, etc.
Le langage OWL utilise un mécanisme de ressources anonymes pour définir des contraintes comme la réunion, l'intersection ou la restriction. Par exemple pour exprimer qu'une personne possède au maximum une date d'anniversaire, on écrira que la classe Personne est une sous-classe d'une classe anonyme de type owl:Restriction comme ci-dessous :
<owl:Class rdf:about="http://example.org/ontology/Personne">
<rdfs:subClassOf>
<owl:Restriction>
<owl:maxCardinality>1</owl:maxCardinality>
<owl:onProperty rdf:resource="http://xmlns.com/foaf/0.1/birthDate"/>
</owl:Restriction>
</rdfs:subClassOf>
</owl:Class>
OWL utilise les URI pour nommer les ressources et RDF(S) pour créer des liens entre elles.
2.2.2.3 - Structure d'une ontologie en OWL
Afin de pouvoir utiliser des termes pour créer une ontologie, il est nécessaire d'indiquer avec précision quels vocabulaires vont être employés, c'est la raison pour laquelle une ontologie commence toujours par une déclaration d'espaces de noms via la balise rdf:RDF. Pour donner un exemple, imaginons que nous voulions écrire une ontologie sur l'humanité :
<rdf:RDF
xmlns = " http://domain.tld/path/humanite#"
xmlns:humanite= " http://domain.tld/path/humanite#"
xmlns:base = " http://domain.tld/path/humanite#"
xmlns:vivant = " http://otherdomain.tld/otherpath/vivant#"
xmlns:owl = " http://www.w3.org/2002/07/owl#"
xmlns:rdf = " http://www.w3.org/1 999/02/22-rdf-syntax-ns#"
xmlns:rdfs = " http://www.w3.org/2000/0 1/rdf-schema#"
xmlns:xsd = " http://www.w3.org/2001/XMLSchema#">
Les deux premières déclarations identifient l'espace de noms propre à l'ontologie que nous allons décrire avec la première qui indique l'ontologie à utiliser dans le cas où aucun préfixe n'est spécifié. La troisième déclaration spécifie l'URI de base de notre ontologie et la quatrième désigne une autre ontologie nommée "vivant", de laquelle nous pourrons utiliser les spécifications. Les quatre dernières déclarations introduisent, quant à elles les vocabulaires OWL, RDF, RDFS et XML Schéma, tous définis par le W3C.
A la suite de la déclaration des espaces de noms viendra se placer la balise d'en-tête de notre ontologie owl:Ontology destinée à débuter la description de l'ontologie :
Ø Les classes
Il existe dans toute ontologie OWL une superclasse prédéfinie, nommée "Thing", dont toutes les autres classes sont implicitement des sous-classes.
Une classe définit un groupe d'individus ayant des caractéristiques similaires. L'ensemble des individus d'une classe est désigné par le terme "extension de classe" et chacun de ces individus est une "instance" de la classe. Il est important de noter que la version OWL FULL est la seule version qui permette qu'une classe soit l'instance d'une autre classe (métaclasse).
Plusieurs syntaxes sont possibles pour déclarer une classe mais nous n'allons pas toutes les citer ici, voici la plus simple d'entres elles pour déclarer une classe "humain" :
<owl:Class rdf:ID="Humain" />
Voici maintenant un autre exemple qui va nous permettre de présenter la notion de sous-classe via la propriété rdfs:subClassOf. Pour cela, imaginons que nous voulions déclarer une classe "ville" en tant que sous-classe de la classe "lieu", nous écririons alors :
<owl:Class rdf:ID="lieu">
<rdfs:label xml:lang="fr">Lieu</rdfs:label>
</owl:Class>
<owl:Class rdf:ID="ville">
<rdfs:label xml:lang="fr">Ville</rdfs:label>
<rdfs:subClassOf rdf:resource="#lieu"/>
</owl:Class>
Ø Les propriétés
Les propriétés OWL donnent la capacité dexprimer des faits au sujet des classes et de leurs instances, par exemple pour du vin, ce pourrait être sa couleur ou sa teneur en sucre. OWL fait la distinction entre deux types de propriétés :
Ø les propriétés dobjets qui permettent de relier des instances entre elles,
Ø les propriétés de types de données qui permettent de relier des individus à des valeurs.
Une propriété dobjet est une instance de la classe owl:ObjectProperty et une propriété de type de données est une instance de la classe owl:DatatypeProperty. Ces deux classes sont elles-mêmes des sous-classes de la classe RDF rdf:Property.
Voici un exemple de propriété d'objet
<owl:ObjectProperty
rdf:ID="estEnseignePar">
<rdfs:domain rdf:resource="#cours"/>
<rdfs:range rdf:resource="#enseignant"/>
<rdfs:subPropertyOf rdf:resource="#implique"/>
</owl:ObjectProperty>
La propriété estEnseignePar rattache la classe "cours" et la classe "enseignant", c'est une extension de la propriété prédéfinie implique.
Voici un exemple de propriété de type de donnée :
<owl:DatatypeProperty
rdf:ID="Age">
<rdfs:range
rdf:resource="http://www.w3.org/2001/XMLSchema#nonNegativeInteger"/>
</owl:DatatypeProperty>
Ici Age fait correspondre, via nonNegativeInteger, aux instances de la classe des entiers non négatifs.
Il existe également de nombreux moyens d'attacher des caractéristiques aux propriétés afin de pouvoir affiner la qualité des raisonnements. Voici pour finir un exemple où l'on place une restriction sur une propriété. On veut ici se restreindre uniquement aux cours enseignés par des enseignants ayant le titre de "professeur".
<owl:Restriction>
<owl:onProperty rdf:resource="#estEnseignePar"/>
<owl:allValuesFrom rdf:resource="#professeur"/>
</owl:Restriction>
Lélément owl:Restriction permet de définir une classe anonyme (non définie par un ID). La restriction peut sexprimer sur le genre ou le domaine dune propriété et sur sa cardinalité.
2.3 - La récupération de l'information : SPARQL
SPARQL (SPARQL Protocol and RDF Query Language) est à la fois un langage d'interrogation et un protocole pour RDF. Dans ce document, nous sommes principalement concernés par le langage, nous n'allons que très brièvement présenter le protocole.
Le protocole SPARQL est décrit sous deux aspects :
Ø en tant qu'interface abstraite, indépendante de réalisations, de mises en uvre et de liaisons à d'autres protocoles,
Ø en tant que liaison HTTP ou SOAP de cette interface.
Le protocole SPARQL contient une seule interface (SparqlQuery), qui contient à son tour une seule opération (query). Il est en général décrit, bien que ce ne soit pas obligatoire, de manière abstraite avec WSDL 2.0 en tant que Web Services mettant en uvre son interface, ses types, ses incidents et ses opérations avec des liaisons HTTP et SOAP. Le protocole SPARQL a été conçu pour être compatible avec le langage d'interrogation SPARQL pour RDF.
Le langage SPARQL peut être utilisé pour exprimer des interrogations à travers diverses sources de données, qu'elles soient stockées nativement via RDF ou vues comme du RDF via un logiciel médiateur (middleware). SPARQL est capable de rechercher des motifs de graphe (graph patterns) ainsi que leurs conjonctions et leurs disjonctions. Les résultats des interrogations SPARQL peuvent être des ensembles de résultats quelconques ou des graphes RDF.
Les spécifications SPARQL sont très proches de RDF car la plupart des formes d'interrogation SPARQL contiennent un ensemble de motifs de triplet (triple patterns) appelé motif de graphe élémentaire (basic graph pattern). Les motifs de triplet sont comparables aux triplets RDF à la différence que dans SPARQL, chaque sujet, prédicat et objet peuvent également être une variable.
SPARQL fonctionne en parfaite synergie avec toutes les technologies du Web sémantique recommandé par le W3C comme RDF(S), OWL, et même GRDDL (Gleaning Resource Descriptions from Dialects of Languages) que nous verrons ultérieurement. Le langage SPARQL inclut également la gestion des adresses IRI.
Concrètement SPARQL est comparable à un langage traditionnel de requêtes comme l'est par exemple SQL mais contrairement à ces langages qui ne peuvent accéder en général qu'à un seul type de source de données, SPARQL est lui capable de rechercher les informations aussi bien dans des bases de données traditionnelles que dans les nouvelles sources de données apportées par le Web sémantique ou le Web 2.0. En plus de cela, il est capable d'interroger ces multiples sources simultanément pour une seule et même requête et de combiner ensuite les résultats pour fournir une réponse riche et précise. Grâce à SPARQL, le Web sémantique devient comparable à une base de données géante.
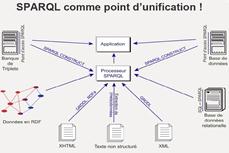
Voici un exemple complet d'utilisation avec la présentation du graphe RDF, de la requête et de la réponse SPARQL. Cet exemple est tiré du site "http://www.lepresscafe.fr/"
Ø Le graphe RDF
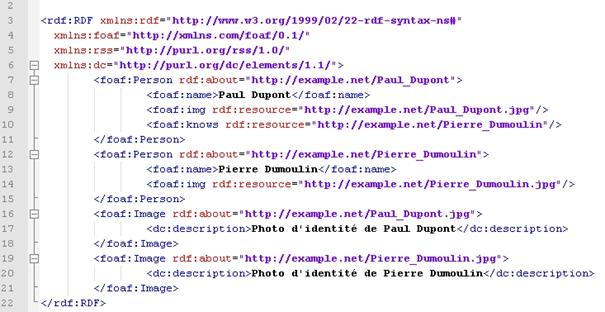
Nous voyons que ce graphe utilise le vocabulaire FOAF pour effectuer la description sémantique des personnes.
Ø La requête SPARQL
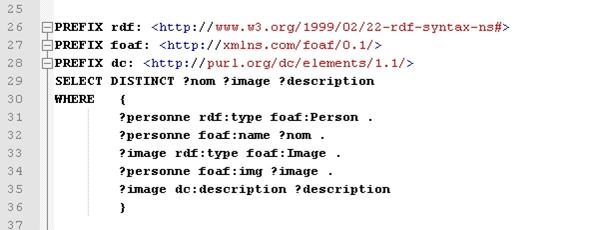
La requête SPARQL est très ressemblante au SQL et l'on comprend immédiatement la requête qui va être de récolter les informations sur les personnes décrites dans le graphe précédent.
Ø Le résultat retourné par SPAQL

Voici le résultat qui est composé, comme on s'y attendait en voyant la requête précédente, des informations récupérées dans le graphe RDF.
Déjà des projets utilisant SPARQL
SPARQL a déjà reçu le soutien de nombreux industriels influents, notamment Hewlett-Packard qui l'a déjà intégré à certains de ses produits. HP a ainsi annoncé la sortie de SDB, un système de base de données basé sur SPARQL pour son framework open source Jena. « Les clients de Hewlett-Packard vont bénéficier d'une meilleure utilisation des informations grâce aux technologies du Web sémantique », a affirmé Jean-Luc Chatelain, directeur de l'activité Software Information Management de HP.
SDB est l'une des quatorze implémentations connues à ce jour de SPARQL. Parmi les autres, on peut citer celle de l'Italien Asemantics chargé de la création d'un moteur de recherche d'images satellite pour le compte de l'Agence Spatiale Européenne (ESA) et d'un autre moteur à destination des autorités maritimes néerlandaises, permettant d'exploiter les données des marées recensées depuis 400 ans.

2.4 - Passerelles entre Web syntaxique et Web sémantique
2.4.1 - RDFa
Le Web actuel est, comme nous l'avons vu, conçu essentiellement pour une consommation humaine et malgré le fait que les données interprétables commencent à faire leurs apparitions, elles sont souvent distribuées dans un fichier séparé et dans un format spécifique. En conséquence, les navigateurs, qui ne voient que l'information de présentation, ne peuvent fournir pour l'instant qu'une aide minimale pour l'analyse et le traitement des données.
Prenons l'exemple d'une page Web classique d'un blog. L'auteur peut, pour présenter son article, indiquer un gros titre, un sous-titre plus petit, un bloc de texte en italique, quelques paragraphes de texte normal et enfin pour finir quelques liens. Les navigateurs représenteront fidèlement ces instructions de présentation mais seul l'esprit humain comprendra que la phrase "En route vers le Web du futur" sera le titre, que le sous-titre représentera le nom de l'auteur, que le texte en italique sera la date de publication et que les liens sont des étiquettes de catégorisation. C'est donc dans le but de combler ce fossé entre le Web actuel et le futur Web sémantique que RDFa (Resource Description Framework in attributes) a vu le jour.
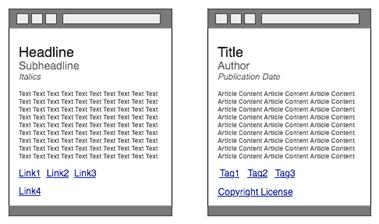
A gauche ce que voient les navigateurs, à droite ce que voient les humains
RDFa fournit à XHTML un ensemble d'attributs simples qui vont lui permettre de prolonger les données visuelles avec des indications compréhensibles par les navigateurs. À ce jour, RDFa n'est spécifié que pour les versions XHTML et supérieur, il n'est en principe pas utilisable avec HTML4. Néanmoins, RDFa prévoit le cas d'utilisation avec HTML4, mais au vu de la diversité des navigateurs, aucune garantie n'est fournie quant au résultat graphique que produira l'ajout de ce type de balise dans la page.
Voyons
maintenant un premier exemple qui va nous permettre de présenter l'utilisation
de RDFa. Imaginons Alice, auteur du blog http://example.com/alice, qui désire que
les articles qu'elle publie soient diffusés sous la licence Creative Commons,
c'est-à-dire que les articles soient réutilisables librement tant que la
paternité des articles lui est reconnue. Dans le pied de page de son blog,
Alice inclut donc le code XHTML nécessaire contenant un lien vers une licence
Creative Commons :
Tout le contenu de ce blog est publié sous licence
<a href="http://creativecommons.org/licenses/by/3.0/">
Creative Commons License
</a>.
Une personne comprendra clairement cette phrase, en particulier la signification du lien qui indique les conditions de la licence du document. Malheureusement, quand Bob visite le blog d'Alice, son navigateur n'y voit qu'un lien ordinaire qui pourrait tout aussi bien pointer vers le blog d'un des amis d'Alice que vers son curriculum vitae. Pour que le navigateur de Bob comprenne que ce lien pointe vers les conditions de licence du document, Alice peut avec RDFa ajouter une saveur (flavor) qui va permettre de définir la relation existante entre la page courante et la page liée.
Pour ajouter une
saveur, il faut utiliser l'attribut rel. La valeur de l'attribut nécessaire à
notre exemple est license, cela
tombe bien car un mot-clé XHTML a été justement réservé à cet effet, le code
deviendra donc :
Tout le contenu de ce blog est publié sous licence
<a rel="license" href="http://creativecommons.org/licenses/by/3.0/">
Creative Commons License </a>.
Avec cette petite modification, le navigateur de Bob comprendra désormais que ce lien a une saveur qui indique la licence du blog.
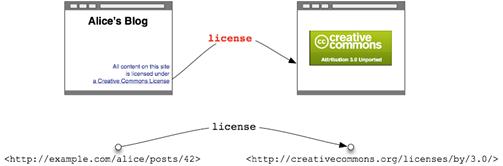
Ravie que le fait d'ajouter une saveur XHTML permette enfin à Bob de trouver facilement la licence de droits d'auteur de son travail, Alice souhaite maintenant que le navigateur de Bob soit capable de différencier les différentes parties (titre, sous titres, date, auteur, ) de ses articles.
Voici le code XHTML qui permet de présenter ses articles :
<div>
<h2>The trouble with Bob</h2>
<h3>Alice</h3>
...
</div>
Pour indiquer que h2 représente le titre de l'article et h3 l'auteur, Alice devra alors utiliser l'attribut property introduit spécifiquement par RDFa dans le but de marquer le texte existant :
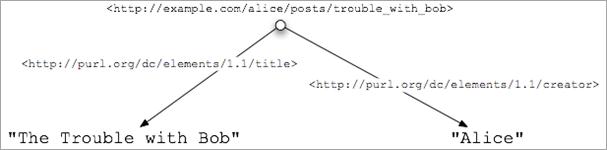
<div xmlns:dc="http://purl.org/dc/elements/1.1/">
<h2 property="dc:title">The trouble with Bob</h2>
<h3 property="dc:creator">Alice</h3>
...
</div>
Dans cet
exemple, Alice a employé dc:creator
et dc:title alors que dans la
logique, elle aurait plutôt utilisé creator
et title. La première raison est
qu'il n'y a aucun mot-clé XHTML réservé pour ces deux concepts. La seconde est
que la propriété property="title" utilisée dans l'exemple précédent, bien qu'elle aurait
permis d'indiquer au navigateur qu'il s'agit d'un titre, n'aurait pas pu
indiquer à quel article ce titre appartenait. Alice a, par conséquent, dû faire
appel à un autre vocabulaire.
Heureusement
pour Alice, la communauté Dublin Core a justement défini un
vocabulaire spécifiquement adapté à la description de documents et il lui a
donc suffi pour l'utiliser de faire appel à l'espace de noms "xmlns:dc=http://purl.org/dc/elements/1.1/" et de l'utiliser ensuite avec les
propriétés dc:creator et dc:title.
En RDFa, tous les noms de propriété sont en réalité des adresses URL :
RDFa utilise principalement les syntaxes XHTML suivantes :
Ø class : pour spécifier le type d'un objet,
Ø id : pour définir l'URI d'un objet dans la page,
Ø rel, rev et href : pour spécifier une relation entre ressources.
RDFa a principalement comme attributs :
Ø about : pour spécifier l'URI de la ressource décrite par les métadonnées. Si elle n'est pas spécifiée, c'est le document en cours qui sera utilisé,
Ø property : pour spécifier une propriété du contenu d'un élément,
Ø content : c'est un attribut optionnel destiné à remplacer le contenu d'un élément quand on utilise l'attribut property,
Ø datatype : c'est un attribut optionnel pour spécifier le type de donnée du contenu.
![]()

 2.4.2 - GRDDL
2.4.2 - GRDDL
GRDDL (Gleaning Resource Descriptions from Dialects of Languages) est un mécanisme destiné à récupérer des éventuelles descriptions de ressources figurant dans un document, XML ou XHTML, afin de les transformer en structure RDF exploitable. Il est obligatoire que les documents soient bien formés pour être exploitables avec GRDDL, c'est-à-dire que le document XHTML ou XML devra dépendre d'un schéma ou d'une DTD.
GRDDL constitue donc un ensemble de mécanismes permettant l'obtention de données RDF à partir d'un document XML ou XHTML classique, et ceci sans contraindre l'auteur à effectuer la formulation RDF normalement nécessaire. Pour cela, GRDDL va confier cette formulation à des algorithmes de transformation spécifiques. GRDDL fonctionne en associant des transformations à un document individuel, soit par inclusion directe de références, soit indirectement par le biais de documents de profils et d'espaces de noms. Pour les dialectes XML, les transformations s'expriment en général avec XSLT 1.0.
Pour utiliser GRDDL dans un document, et ainsi relier les données du document au modèle de données RDF, l'auteur doit uniquement faire deux modifications par rapport à son document classique. Premièrement, il doit ajouter un attribut profile à l'élément head afin d'indiquer que son document contient des métadonnées GRDDL. L'adresse URI du profil de GRDDL est "http://www.w3.org/2003/g/data-view", et en incluant cette adresse URI dans son document, l'auteur déclare que son balisage peut être interprété avec GRDDL.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN"
"http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head profile="http://www.w3.org/2003/g/data-view">
<title>Robin's Schedule</title>
</head>
<body>
Deuxièmement, il doit ajouter un élément link contenant la référence de la transformation GRDDL spécifique pour convertir le code HTML en RDF. L'auteur a le choix entre écrire sa propre transformation GRDDL ou bien utiliser une transformation existante. Dans cet exemple, il utilise une transformation spécifique aux agendas (hCalendar).
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN"
"http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head profile="http://www.w3.org/2003/g/data-view">
<title>Robin's Schedule</title>
<link rel="transformation" href="http://www.w3.org/2002/12/cal/glean-hcal"/>
</head>
<body>
L'attribut rel de l'élément link a pour valeur l'atome transformation, et l'attribut href donne l'adresse URI de la transformation GRDDL pour extraire le RDF.
Voici un descriptif des étapes de transformation d'un document XHTML au format RDF via GRDDL. Le document repose ici sur le vocabulaire Dublin Core :
Ø Le document XHTML de base
<html xmlns="http://www.w3.org/1999/xhtml">
<head profile="http://www.w3.org/2003/g/data-view">
<title>Un document</title>
<link rel="transformation"
href="http://www.w3.org/2000/06/dc-extract/dc-extract.xsl" />
<meta name="DC.Subject"
content="ADAM; Simple Search; Index+; prototype" />
</head>
...
</html>
Ø La transformation GRDDL

Ø Le résultat de la transformation
<rdf:RDF xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about="">
<dc:subject>ADAM; Simple Search; Index+; prototype</dc:subject>
</rdf:Description>
</rdf:RDF>
À la lecture du document, les clients pourront suivre les liens à travers le Web en utilisant les techniques décrites dans la spécification GRDDL pour découvrir les transformations appropriées.
Il est
possible de voir un exemple réel sur le site http://ns.inria.fr/grddl/rdfa/ , si
l'on clique sur l'image ![]() , on obtient la transformation RDF suivante
:
, on obtient la transformation RDF suivante
:

Il est à noter que les pages avec microformats (approche du Web sémantique version Web 2.0 que nous ne verrons pas dans ce rapport car très proche de RDFa), bien que très utilisées, ne seront probablement pas des pages XHTML valides. Dans ce cas, il faudra utiliser au préalable un programme comme par exemple "Tidy" qui rendra la page valide avant de lui affecter la transformation.
III- Les standards spécifiques aux Web Services
Malgré le fait que l'intérêt du monde informatique pour la sémantique soit encore très récent, et par conséquent celui des Web Services sémantiques encore plus, des groupes de travail du W3C sont néanmoins déjà sur le qui-vive, un certain nombre de recherches ont donc été lancées dans ce domaine et des solutions commencent à voir le jour.
Ces solutions sont principalement, comme pour la sémantique vue précédemment, axées autour de deux solutions. La première est l'utilisation d'un langage permettant une description complète de l'information de manière sémantique et la seconde est l'ajout d'annotations sémantiques aux langages existants.
Nous allons maintenant faire un rapide tout d'horizon de ces technologies, mais nous ne les développerons pas en détails car la plupart, à l'instar des WS-*, ne sont encore qu'en cours d'élaboration et pour les technologies déjà en place, elles reposent principalement sur les principes sémantiques vus précédemment avec en complément des spécifications adaptées aux Web Services.
3.1 - OWL-S
Disposer d'une ontologie ne suffit pas pour pouvoir l'exploiter au sein d'un Web Services car il est obligatoire de disposer d'une interface qui fasse le lien entre les deux. C'est donc dans l'optique de réaliser cette interface que le langage OWL-S (Web Ontology Language for Web Services), basé sur le langage de description d'ontologies OWL, a été conçu. OWL-S est une recommandation du W3C.
Plus précisément, OWL-S fournit un ensemble de marqueurs permettant de décrire des propriétés et des capacités adaptées aux Web Services. Il a été conçu pour faciliter l´automatisation des tâches leurs étant relatives, c'est-à-dire principalement leurs découvertes, leurs exécutions, leurs compositions et leurs interopérabilités. OWL-S est également compatible avec des formats de descriptions syntaxiques tels que WSDL.
Une description OWL-S se compose de trois éléments principaux :
Ø le serviceProfile : qui permet de décrire les fonctionnalités du Web Services,
Ø le serviceModel : qui permet de détailler la sémantique des données échangées,
Ø le serviceGrounding : qui permet de définir les modalités d´accès au Web Services (encodage des données échangées, protocoles de communication utilisés, ).
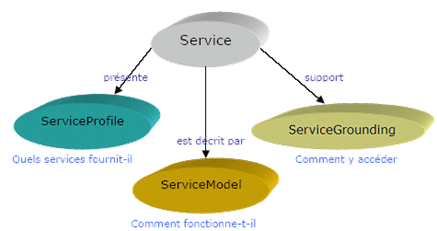
Il est à noter que la classe Service fournit le point d´entrée pour la description du Web Services et qu'il n´existe qu´une seule instance de cette classe par Web Services.
OWL-S permet également de spécifier deux contraintes de cardinalités :
Ø un Web Services doit être décrit au plus par un ServiceModel,
Ø un Web Services doit posséder un seul ServiceGrounding.
OWL-S recommande la séparation entre les vues de haut niveau et les vues de bas niveau pour la description des données échangées entre Web Services. La vue de haut niveau, appelée aussi vue abstraite, permet de présenter les éventuelles ontologies attachées au Web Services, alors que la vue de bas niveau, appelée aussi vue concrète permet de décrire la représentation physique du Web Services, c'est-à-dire les types de données et les protocoles utilisés. Cette séparation permet de renforcer le rôle des ontologies en permettant la représentation de plusieurs vues concrètes pour une seule et même vue abstraite.
3.2 - WSMO
Larchitecture WSMO (Web Services Modeling Ontology) est une architecture conceptuelle visant à expliciter la sémantique des Web Services. Elle est organisée autour de quatre éléments principaux dont voici le schéma :
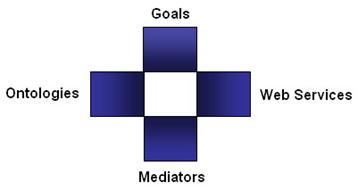
Ø les Médiateurs sont utilisés pour résoudre les problèmes éventuels dincompatibilité, tels que par exemple les incompatibilités de terminologies des données ou les incompatibilités de protocoles. Il existe quatre familles de médiateur :
· les GG-médiateurs (Goal / Goal) permettent deffectuer la médiation entre deux objectifs en se basant sur les ontologies dobjectifs disponibles,
· les WG-médiateurs (Web Services / Goal) permettent d'établir les correspondances entre les fonctionnalités du Web Services et les requêtes des utilisateurs,
· les WW-médiateurs (Web Services / Web Services) permettent de résoudre les conflits entre Web Services (données, protocoles, ),
· les OO-médiateurs (Ontology / Ontology) sont destinés à résoudre les conflits entre ontologies, c'est-à-dire à établir des correspondances entre les terminologies contenues dans les différentes ontologies. Tous les types de médiateurs énoncés ci-dessus peuvent utiliser un OO-médiateur pour résoudre le conflit sémantique qu'ils sont en train de traiter.
Ø les Web Services y sont définis comme des entités pouvant être traitées par un ordinateur et qui fournissent obligatoirement une fonctionnalité. Pour cela une description est associée à chaque Web Services afin d'y décrire sa fonctionnalité, son interface, et toutes autres informations internes nécessaires à son utilisation,
Ø les Objectifs servent à décrire les souhaits des utilisateurs en termes de fonctionnalités. Les objectifs sont donc des vues orientées utilisateur du processus dutilisation du Web Services. Ce sont des entités à part entière du modèle WSMO,
Ø les Ontologies fournissent la terminologie de référence aux éléments de WSMO afin de spécifier un vocabulaire du domaine de connaissance interprétable par les machines. Contrairement à OWL-S, WSMO considèrent les médiateurs comme étant des composants centraux de son architecture.
3.3 - SAWSDL
SAWSDL (Semantic Annotation for WSDL) est un mécanisme d'annotations sémantiques qu'il est possible d'intégrer directement au sein du document WSDL d'un Web Services. SAWSDL est aujourd'hui reconnue comme étant une extension de WSDL 2.0 et est devenue une recommandation W3C depuis le mois d'août 2007.
Grâce à SAWSDL, il est donc possible d'établir un lien entre un Web Services et une spécification sémantique directement à partir de son fichier de description WSDL.
SAWSDL n'est pas un langage de description de concept sémantique comme l'est par exemple une ontologie, SAWSDL est uniquement un système d'annotations sémantiques qui a pour but de définir la façon dont une annotation doit être réalisée pour pouvoir être interprétée par une machine et n'impose par conséquent aucun langage pour décrire le concept sémantique sur lequel le Web Services va se reposer.
Les principes de conception pour SAWSDL selon le W3C :
Ø il permet des annotations sémantiques pour les Web Services en s'appuyant sur les possibilités d'extension de WSDL,
Ø il diagnostique la représentation sémantique des langues,
Ø il permet des annotations sémantiques aussi bien pour la découverte des Web Services que pour leurs invocations.
SAWSDL définit trois attributs à l'extensibilité WSDL 2.0 pour permettre l'annotation sémantique des composants WSDL :
Ø un attribut nommé modelReference, qui permet de préciser l'association entre une composante WSDL et un concept sémantique. Cet attribut est utilisé en particulier pour annoter les schémas XML des définitions de types, de déclarations, d'attributs ainsi que pour les interfaces, opérations et défauts WSDL,
Ø deux attributs, nommés liftingSchemaMapping et loweringSchemaMapping, qui sont ajoutés aux schémas XML pour la spécification des correspondances entre sémantique de données et XML. Ces mappages peuvent être utilisés pendant le service d'invocation.