

PREREQUIS TECHNIQUES


I - Le principe Client / Serveur
De nombreuses applications fonctionnent aujourd'hui dans un environnement client/serveur. Dans un tel environnement, les diverses machines qui composent le réseau, appelées machines clientes ou plus simplement clients, sont toutes connectées à un même ordinateur surpuissant appelé serveur, qui centralisera et stockera l'information dans le but de la restituer aux clients en cas de demande.
![]()
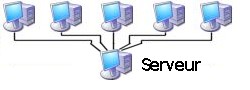
Ø Avantages de cette architecture :
des ressources centralisées : le serveur gère les ressources communes à tous les utilisateurs et évite ainsi les problèmes de redondance,
une meilleure sécurité : les données sensibles sont stockées sur le serveur qui est en principe très sécurisé, le nombre de points d'entrée est par conséquent diminué,
une administration simplifiée : toute la gestion du réseau s'effectue à partir du serveur,
une facilité d'évolution : possibilité d'ajouter ou de supprimer des machines sur le réseau sans en perturber le fonctionnement.
Ø Inconvénients de cette architecture :
un coût d'exploitation élevé : consommation de bande passante élevée, des kilomètres de câbles peuvent être nécessaires, prix élevé du serveur, etc. ,
un point sensible : si le serveur tombe en panne, le réseau est paralysé.
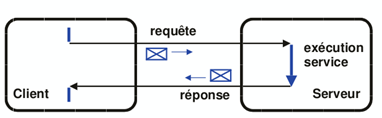
Afin de pouvoir communiquer, le client et le serveur utilisent un système de requêtes / réponses dont le schéma simplifié est présenté ci-dessous. Les requêtes, donc les demandes d'information, sont toujours à l'initiative des clients. Le serveur, quant à lui, est dans un état d'attente permanent et se réveille dès l'arrivée d'une requête.
II - Le modèle TCP/IP
Le modèle TCP/IP, composé comme son nom l'indique des deux protocoles TCP (Transmission Control Protocol) et IP (Internet Protocol), a été créé en 1976 par l'Agence Américaine de la Défense. TCP/IP s'est alors progressivement imposé et est aujourd'hui devenu le modèle de référence, en lieu et place du modèle OSI (Open Systems Interconnection), pour tout ce qui concerne les règles de communication sur Internet. TCP/IP se base sur la notion d'adressage IP pour acheminer les paquets de données, ce qui sous-entend que chaque machine reliée au réseau doit disposer d'une adresse IP unique.
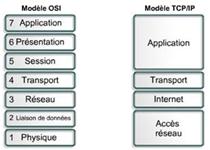
Comparaison entre modèle OSI et TCP/IP
Afin de pouvoir appliquer ce modèle sur toutes les machines et de le rendre par conséquent indépendant du système d'exploitation, il a été décomposé en plusieurs couches effectuant chacune, dans un ordre précis, une tâche particulière. Pour cela, chaque couche encapsule les données de sa couche inférieure avec des en-têtes qui lui sont propres et pour récupérer les données, il suffira d'effectuer ce processus dans l'ordre inverse sur la machine réceptrice. Le terme de couche est utilisé pour évoquer le fait que les données qui transitent sur le réseau devront traverser plusieurs niveaux de protocoles.
2.1 - Les couches de TCP/IP
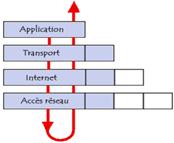
TCP/IP est composé de quatre couches :
Ø couche Accès réseau : elle spécifie le format d'envoi des données sur le réseau,
Ø couche Internet : elle choisit la route pour acheminer les données,
Ø couche Transport : elle est responsable du bon acheminement des données,
Ø couche Application : elle englobe les applications standards du réseau (SMTP, FTP, ...).
Suivant les couches où se trouvent le paquet de données, son appellation change et devient :
Ø
 message
dans la couche Application,
message
dans la couche Application,
Ø segment dans la couche Transport,
Ø datagramme dans la couche Internet,
Ø trame dans la couche Accès réseau.
2.2 - Le protocole IP
Sur internet, les informations envoyées sont, comme nous venons de le voir, découpées en morceaux de plus petites tailles par les différentes couches et encapsulées au sein de paquets. Chacun de ces paquets est ensuite traité de façon autonome et indépendante. C'est à dire que les différents paquets composant une même information ne seront pas forcément acheminés de la même façon et ne suivront pas obligatoirement le même chemin. C'est ici que le protocole IP (Internet Protocol) intervient car c'est lui qui sera chargé de choisir le chemin, selon le principe de la "livraison au mieux", que va emprunter chaque paquet pour arriver à sa destination et cela en temps réel en fonction de l'état du réseau.
Le protocole IP utilise 3 caractéristiques principales pour fonctionner :
Ø l'adresse IP qui représente l'adresse IP de la machine hôte,
Ø le masque de sous-réseau qui permet au protocole IP de savoir sur quel réseau est située la machine hôte,
Ø la passerelle par défaut qui permet de sortir du réseau dont fait partie la machine hôte.

IP est considéré comme étant un protocole non fiable. Cela ne signifie pas qu'il n'envoie pas correctement les données sur le réseau mais simplement qu'il ne dispose d'aucun système de contrôle contre l'altération ou la perte de données. En termes de fiabilité, le seul service offert par IP est de s'assurer que les en-têtes ne comportent pas d'erreurs grâce à un contrôle checksum. Si l'en-tête d'un datagramme comprend une erreur, il sera détruit mais pas retransmis et aucune notification ne sera envoyée à l'expéditeur.
La raison principale de cette absence de gestion de la fiabilité au niveau IP est la volonté de réduire le niveau de complexité des routeurs afin d'augmenter leurs rapidités au maximum. C'est notamment pour cette raison qu'IP est associé au protocole de transport TCP chargé lui, d'assurer le bon acheminement des transmissions et de l'intégrité des données.
Du fait de sa démocratisation et de son faible coût, IP est devenu la référence des protocoles réseaux et a encore de beaux jours devant lui, d'autant plus qu'il est sur le point migrer dans sa version IPv6 pour combler ses lacunes comme, par exemple, le manque cruel d'adresse IP disponible, l'absence d'une sécurité intégrée ou encore l'absence de qualité de service (QoS). IPv6 sera capable d'offrir environ 10000 adresses IP au mètre carré n'importe où sur la planète.
2.3 - Le protocole TCP
TCP (Transmission Control Protocol) est un protocole qui va permettre d'établir une connexion fiable entre deux machines. Pour pouvoir communiquer, les deux machines devront donc commencer par établir une connexion. La machine qui demandera l'établissement de la connexion sera alors appelée client, tandis que la machine réceptrice sera appelée serveur. Avec TCP, nous somme donc en présence d'un environnement Client / Serveur.
Pour assurer cette fiabilité, TCP utilise un système d'accusé de réception qui va permettre à la fois au client et au serveur de s'assurer du bon déroulement de l'échange. Pour cela, lors de l'émission d'un segment, un numéro d'ordre (appelé aussi numéro de séquence) lui est associé et à sa réception, la machine réceptrice retournera un accusé de réception (ACK) accompagné du numéro d'ordre du segment concerné.
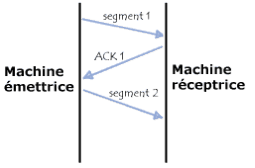
Si aucun accusé de réception n'est envoyé au bout d'un certain temps, TCP considérera que le paquet a été perdu ou détruit et la machine émettrice renverra à nouveau le paquet. Dans le cas où le premier paquet arriverait tout de même à destination, la machine réceptrice saura grâce au numéro d'ordre qu'il s'agit d'un doublon et ne conservera que le dernier segment reçu.
Afin de désengorger le réseau, il est possible de limiter le nombre d'accusés de réception en définissant le nombre de paquets reçus avant de devoir émettre un accusé de réception. On appelle cette méthode "la méthode de la fenêtre glissante".
![]()
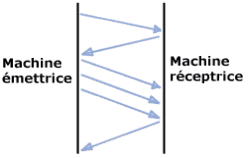
La taille de cette fenêtre n'est pas fixe et le serveur peut inclure, dans ses accusés de réception, un message permettant d'indiquer la taille la mieux adaptée en fonction de l'encombrement du réseau. TCP permet enfin l'initialisation et la fin d'une communication de manière courtoise.
III - Le protocole HTTP
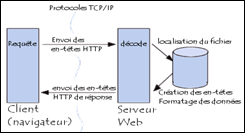
Le protocole HTTP (HyperText Transfer Protocol) est le protocole sans lequel aucune transaction ne pourrait exister sur le Web. C'est le langage qui permet aux programmes clients, généralement des navigateurs (Firefox, Internet Explorer...), de communiquer avec les serveurs Web (Apache, IIS...) pour en solliciter une action. HTTP est donc une implémentation de type Client / Serveur.
Le protocole HTTP par lui même est sans connexion et sans état, c'est-à-dire que chaque requête est considérée de manière indépendante et que le serveur ne mémorise aucun contexte. Cela n'interdit pas à un serveur Web de simuler une connexion et de maintenir un état, mais ces pratiques doivent être limitées au maximum afin de respecter les principes architecturaux du Web.
Néanmoins la plupart du temps les applications Web, comme toutes autres applications, ont besoins de maintenir un contexte pour rester viables et si le protocole ne le gère pas, elles seront contraintes de le faire elles-mêmes. Une des solutions est alors de stocker les informations nécessaires directement sur le client avec, par exemple des variables ou des cookies, de façon à ce que le client envoi ces informations avec toutes les futures requêtes. Une autre solution est de stocker le contexte directement sur le serveur et dans ce cas le client n'aura qu'à joindre dans ses requêtes une information permettant de le retrouver. Il sera alors nécessaire d'utiliser directement les méthodes POST, PUT et DELETE du protocole HTTP pour le gérer.
3.1 - Les transactions HTTP
HTTP a principalement pour but de permettre un transfert de fichiers, essentiellement au format HTML, localisés via une adresse communément appelée URL. La connexion entre le client et le serveur se fait en deux temps à travers le port 80 :
1 - le navigateur effectue une requête HTTP,
2 - le serveur traite la requête puis envoie une réponse HTTP.
3.1.1 - Les requêtes
Une requête HTTP est un ensemble de lignes envoyées au serveur par le navigateur, elle comprend :
une ligne de commande : elle comprend trois éléments qui sont la méthode HTTP à utiliser, l'URL du document appelé et la version de HTTP utilisé par le client,
les en-têtes de la requête : ce sont des lignes facultatives permettant de donner des informations supplémentaires sur la requête et le client (type navigateur, type système d'exploitation, type connexion...),
le corps de la requête : le corps doit être séparé des lignes précédentes par une ligne vide. Il permet de transmettre par exemple des valeurs d'un formulaire avec la méthode POST.
Voici un exemple de requête HTTP
GET /index.html HTTP/1.1 // méthode HTTP, fichier demandé, version de HTTP
Host: developpeur.cs2i.com // adresse sans le préfixe « http:// »
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; fr; rv: 1.8.1.1) Gecko/20061204
Firefox/2.0.0.1 // navigateur Web utilisé
Connection: close // état de la connexion
[ligne vide] // pour séparer l'en-tête du corps éventuel
3.1.2 - Les réponses
Une réponse HTTP est un ensemble de lignes envoyées au navigateur par le serveur, elle comprend :
une ligne de statut : elle comprend trois éléments qui sont la version du protocole HTTP utilisée, le code du statut de la réponse et la signification du code,
les en-têtes de la réponse : ce sont des lignes facultatives permettant de donner des informations supplémentaires sur la réponse et le serveur (date, type de serveur ),
le corps de la réponse : il contient le document demandé.
Voici un exemple de réponse :
HTTP1.0 200 OK // version de HTTP, code réponse , statut réponse
Date: Fri, 29 Dec 2006 15:48:35 GMT //Date de début de transfert des données
Server: Apache // Caractéristiques du serveur ayant envoyé la réponse
Content-Type: text/html // Type de contenu du corps de la réponse
Content-Length: 1245 // Longueur du corps de la réponse
Last-Modified : Fri, 14 Jan 2000 08:25:13 GMT //date de dernière modification
ligne vide] // pour signifier la fin de l'en-tête
3.1.3 - Les codes de réponse possibles
Les codes de réponse sont très importants car ils représentent le statut de la transaction et permettent donc de savoir si une requête a échoué, réussit ou est redirigée. Ce code est constitué de trois chiffres, le premier indique la classe de statut et les suivants la nature exacte de l'erreur.
|
Code |
Message |
Description |
|
10x |
Message d'information |
Non utilisé dans la version 1.0 du protocole |
|
20x |
Réussite |
Bon déroulement de la transaction |
|
30x |
Redirection |
La ressource n'est plus à l'emplacement indiqué |
|
40x |
Erreur due au client |
Requête client incorrecte |
|
50x |
Erreur due au serveur |
Erreur interne du serveur |
Les codes de classe 2 indiquent que lopération sest correctement effectuée, le plus courant est le code 200 (OK). Les codes de classe 3 indiquent que lobjet demandé a été déplacé, il faut donc changer dURL ou de méthode pour accéder au contenu de cette ressource. La classe 4 sert lorsque le client a commis une erreur (la classique erreur 404 Not found lorsque lobjet demandé nexiste plus ou 403 FORBIDDEN après la saisie dun mauvais mot de passe). La classe 5 signifie une erreur au niveau du serveur comme par exemple un bug dans un script CGI.
3.2 - Les méthodes HTTP
HTTP permet d'effectuer 8 types de requêtes différentes sur le serveur:
Ø GET : c'est la méthode la plus courante pour demander une ressource. Une requête GET ne doit pas modifier la ressource et il doit être possible de la répéter sans effets néfastes.
ð Exemple d'utilisation: ouvrir un document PDF,
Ø HEAD : cette méthode demande des informations sur la ressource mais sans demander la ressource elle-même. Elle est donc identique à GET sauf qu'elle ne renvoie que les en-têtes.
ð Exemple d'utilisation: tester si un document existe,
Ø POST : cette méthode doit être utilisée lorsqu'une requête modifie la ressource ou lorsque l'on envoi des informations au serveur.
ð Exemple d'utilisation: envoyer les données d'un formulaire HTML au serveur,
Ø OPTIONS : cette méthode permet d'obtenir les options de communication d'une ressource ou du serveur en général.
ð Exemple d'utilisation: connaître les méthodes acceptées par une ressource,
Ø CONNECT : cette méthode permet d'utiliser un proxy comme un tunnel de communication.
ð Exemple d'utilisation: établir une connexion sécurisée via HTTPS à travers un serveur d'autorisation
Ø TRACE : cette méthode demande au serveur de retourner les informations qu'il vient de recevoir, dans le but de tester et d'effectuer un diagnostic sur la connexion.
ð Exemple d'utilisation: demander à un proxy de se déclarer dans les en-têtes,
Ø PUT : cette méthode permet d'ajouter une ressource sur le serveur.
ð Exemple d'utilisation: ajouter d'une image sur le serveur,
Ø DELETE : cette méthode permet de supprimer une ressource du serveur.
ð Exemple d'utilisation: supprimer un document PDF sur le serveur
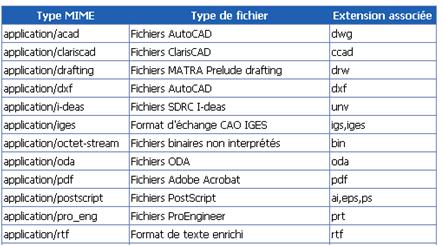
Les documents transmis par les requêtes et les réponses sont décrits en respectant les Types MIME, rebaptisés récemment "Internet Media Types". Ils permettent d'indiquer au navigateur le type de documents qui sera envoyé dans la requête. Voici quelques exemples de Types MIME :
IV - Le langage HTML
Développé par le fondateur du Web Tim Berners-Lee en 1989, HTML est devenu le format de fichier le plus populaire et le plus répandu au monde. Il est aujourd'hui devenu un standard dont les recommandations ont été publiées par le consortium international W3C (World Wide Web Consortium) et sa version actuelle est HTML 4.01.

Tim Berners-Lee, fondateur du Web
HTML est un langage qui permet de créer, lier et afficher des pages Web à l'aide de balises de formatage. Par exemple, lorsque vous lisez une page quelconque sur Internet, celle-ci est en réalité écrite en langage HTML puis convertit par votre navigateur pour être affichée dans un format compréhensible par l'être humain.
Voici le code minimum pour construire une page Web. Cette page n'affiche rien car aucune information ne figure dans le corps de la page (entre les balises <body> et </body>) mais son format est tout à fait correct.
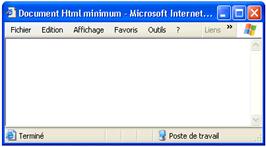
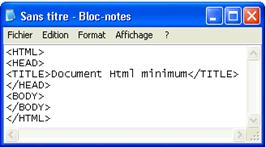
Une page Web minimale
Le langage HTML, du fait des nouvelles possibilités d'Internet, a toutefois rapidement montré ses limites car il ne permet uniquement la description de contenus statiques. C'est pour cette raison que HTML est aujourd'hui souvent utilisé en combinaison avec un langage dynamique tel que par exemple PHP, Ruby, ASP ou encore Java. Un autre point négatif d'HTML est qu'il ne permet pas la séparation du contenu et de la forme, c'est ainsi qu'XML commence lui aussi à le remplacer dès que les applications Web deviennent complexes.
A l'heure actuelle, le langage HTML cède doucement sa place au profit du XHTML qui est une version HTML allégée et mieux adaptée aux nouveaux appareils mobiles. Néanmoins, aucun changement radical n'est présent entre ces deux versions pour une utilisation de base.
V - Le langage XML
XML (eXtensible Markup Language) a été mis au point par le XML Working Group et sa première version, XML 1.0, a été publiée le 10 février 1998. XML est une recommandation du W3C.
Le langage XML est un dérivé simplifié du SGML (Standard Generalized Markup Language), un langage de codage de données dont l'objectif est, lors d'un échange entre systèmes informatiques, de réussir à transférer simultanément les données et leurs structures. SGML permet théoriquement de coder n'importe quel type de donnée et XML, si nous voulions le présenter simplement, est en quelques sortes une version de SGML utilisable sur le Web.
XML est au premier abord comparable à un HTML amélioré où l'on aurait la possibilité de définir de nouvelles balises. En réalité, XML et HTML sont totalement différents car les balises du langage XML décrivent le contenu du document alors que les balises HTML en décrivent la forme. Pour décrire la forme, XML utilise en général un document XSL (eXtensible Stylesheet Language) qui contiendra les informations nécessaires à l'affichage graphique du document.
XML permet donc de séparer le contenu de la présentation. Cette information, qui peut paraître anodine, représente au contraire la grande force du langage XML car cela signifie que grâce à XML, il est possible de partager un même document entre plusieurs applications différentes sans devoir effectuer le moindre changement. Ce sera ensuite aux applications de gérer la façon dont elles traiteront ce document XML. Par exemple, un même fichier XML pourra tout aussi bien devenir un document HTML qu'un document PDF.
Un autre point fort de XML est sa capacité à pouvoir décrire n'importe quel domaine et ceci quel que soit le type de données utilisées. Il peut donc même être utilisé pour définir d'autres langages. Avec XML, il est maintenant possible de structurer et de poser le vocabulaire et la syntaxe des données de n'importe quel document. Pour cela, notre document XML n'aura qu'à reposer sur un document qui décrira les données à utiliser, c'est-à-dire sur une DTD (Document Type Definition) ou sur un schéma XML adapté.

Grâce à XML, il est devenu possible déchanger de linformation sans connaître le composant logiciel qui traitera cette information. Pour cela, il les documents XML échangés sont capables de s'auto-décrire afin de s'interfacer de façon totalement autonome. XML facilite donc grandement la communication entre les différents composants d'un système d'information.
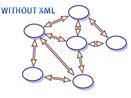
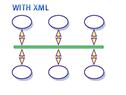
5.1 - La séparation du fond de la forme
Comme XML est utilisé pour décrire le contenu des documents sans se soucier de leurs apparences, la mise en page des données est confiée à un langage tiers. Il existe principalement deux solutions pour mettre en forme un document XML :
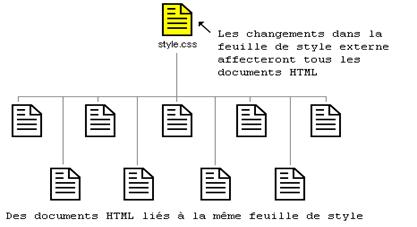
Ø CSS (Cascading StyleSheet) : l'utilisation des CSS est une recommandation du W3C. Ce sont des fichiers appelés "feuilles de style" dans lesquels figurent le code nécessaire à la description graphique des documents HTML, XHTML ou XML. C'est la solution la plus utilisée actuellement pour la description graphique des sites Web.
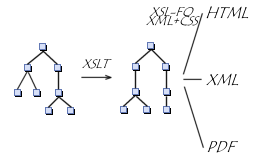
Ø XSL (eXtensible StyleSheet Language) : XSL est le langage recommandé par le W3C pour la mise en forme de document XML. Il est comparable à CSS à la différence qu'il est beaucoup plus puissant que ce dernier car il permet, en plus de la modification de l'aspect graphique, de modifier totalement la structure d'un document XML et ainsi de générer un même document dans une multitude de formats (PDF, PostScript, HTML, Tex, RTF ...) sans devoir changer le document source.
Actuellement XSL possède deux composantes, le XSLT (eXtensible StyleSheet Language Transformation) et le XSL/FO (eXtensible Stylesheet Language Formatting) respectivement utilisés pour la transformation du document source XML et pour le changement de format graphique de la transformation. Dans les deux cas, XSL utilise Xpath pour extraire les données souhaitées. XPath est une syntaxe particulière qui permet de désigner uniquement des portions spécifiques de code dans un document XML.
5.2 - La structure des documents XML
Un document XML est fondamentalement de type "texte", par opposition à d'autres structures informatiques qui peuvent être de type binaire. Pour produire un document HTML à partir de données en utilisant le format XML, il est, comme nous l'avons vu, nécessaire d'écrire au moins deux fichiers. Le premier qui contiendra les données (le fichier XML) et le second qui comprendra les informations nécessaires à la représentation des données (le fichier XSL(T)). Un troisième fichier est recommandé si la base de données est étendue ou complexe pour en expliquer l'organisation (la DTD).
Un document XML est structuré en 3 parties :
Ø le prologue : il permet d'indiquer la version de la norme XML utilisée (obligatoire) ainsi que le jeu de caractères (facultatif). Ex : <?xml version="1.0" encoding="ISO-8859-1"?>. Le prologue peut également contenir des informations facultatives d'instructions de traitement,
Ø la déclaration de type de document (DTD) : XML fournit un moyen de vérifier la syntaxe d'un document grâce aux DTD (Document Type Definition). Il s'agit d'un fichier décrivant la structure (aussi appelée la grammaire) des documents y faisant référence grâce à un langage adapté. Ainsi un document XML doit suivre scrupuleusement les conventions de notation et peut éventuellement faire référence à une DTD décrivant l'imbrication des éléments. Un document respectant les règles XML sera alors appelé document bien formé et un document XML possédant une DTD et étant conforme à celle-ci sera appelé document valide,
Ø l'arbre des éléments : C'est le véritable contenu du document XML, il est constitué d'une hiérarchie de balises comportant éventuellement des attributs. Un attribut est une paire clé / valeur : <balise clé="valeur">. Toutes les données sont à encapsuler entre une balise ouvrante <balise> et fermante </balise>. Un élément vide est constitué d'une balise unique spécifique <balise/>.
Voici un exemple de fichier XML minimaliste
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE faire_course SYSTEM "caddy.dtd">
<chariot>
<articles>
<article no="1"> Pommes </article >
<article no="2"> Bananes </article>
<article no="3"> Poires </article>
</articles>
</chariot>
5.3 - Le décodage d'un document XML
Afin de pouvoir interpréter et récupérer les données contenues dans un document XML, il est nécessaire d'utiliser un outil appelé analyseur syntaxique (parser en anglais) permettant de parcourir le document et d'en extraire les informations. Dans le cas de XML, on parlera alors de parseur XML
On distingue deux types de parseurs XML :
Ø les parseurs hiérarchiques : DOM
DOM (Document Object Model) est une norme établit par le W3C et est par conséquent disponible pour toutes les plateformes et langages de programmation. Ce type de parseur reconstruit la totalité de la hiérarchie du document XML en mémoire vive pour ensuite permettre l'accès aux différents éléments. Cette technique est un peu lourde du fait de la mise en mémoire mais en contre partie, les éléments, une fois en mémoire, sont accessibles directement sans avoir à re-parcourir le document. Pour que DOM soit efficace, il faut que la taille de la structure du document XML ne soit pas supérieure à ce que peut contenir la mémoire vive de l'ordinateur. L'intérêt majeur de DOM repose donc dans la possibilité d'aller et venir dans l'arborescence,
Ø les parseurs événementiels : SAX
SAX (Simple API for XML) est également disponible pour la majorité des plateformes et des langages de programmation. Le principe de fonctionnement de ce parseur est de transformer un document XML en un flux d'évènements qui pourront être déclenchés ou non au fur et à mesure du parcours du document XML. Comme ce parseur ne mène qu'une recherche sélective et n'interprète que ce qui est nécessaire, il a l'avantage de lire le code par petites portions, ce qui lui évite de le charger en mémoire. SAX est donc particulièrement bien adapté pour les structures de grandes tailles.
Il est très difficile de dire lequel de ces deux types de parseurs est le meilleur car ils ont plutôt tendance à se compléter qu'à se faire concurrence.
5.4 - Les espaces de noms
XML définit un système permettant d'utiliser des balises identiques mais ayant des descriptions différentes au sein d'un même document grâce à la notion d'espaces de noms (namespaces). Les espaces de noms ont été crées pour assurer l'unicité des éléments XML.
Pour comprendre, supposons que nous utilisons la balise <livre> dans un document XML. Cela veut dire que cette balise a été décrite quelque part dans un XML Schéma ou dans une DTD. Imaginons maintenant que nous soyons amenés à récupérer des informations d'un autre document XML pour le fusionner avec le notre, mais que ce document contienne lui aussi une balise <livre>. Le problème ici est que la balise <livre> n'a pas forcément été décrite de la même façon pour les deux documents. Il y'a donc de forte chance que le résultat obtenu ne soit pas celui attendu car dans le document fusionné, lorsque le parseur rencontrera la balise <livre>, il ne saura pas à quel Schéma ou DTD se référer. C'est pourquoi les espaces de noms ont été créés car ils vont nous permettre de spécifier pour chacune des balises <livre>, la DTD ou le Schéma à utiliser. Nous pourrions donc déclarer (à l'endroit prévu à cet effet dans le document XML) par exemple les deux espaces de noms :
xmlns
livreA="http://www.description_livre_1.org/"
xmlns
livreB="http://www.description_livre_2.org/"
Nous pourrons ainsi spécifier pour chaque balise <livre> à quel schéma ou DTD se référer
<livreA:livre>
=> pour faire référence à la description 1
<livreB:livre>
=> pour faire référence à la description 2
L'utilisation d'espaces de noms n'est pas obligatoire mais elle est recommandée.
VI - URI / URL / URN
Internet est composé de plusieurs milliards de pages stockées sur différents serveurs au quatre coins de la planète. Chacune de ces pages Web ou ressources en ligne (image, vidéo, musique....), est repérée par une adresse unique appelée communément URL. Pour accéder à une page il suffira donc simplement de spécifier cette URL (Uniform Resource Locator) au sein d'un navigateur Web.
Depuis 1998, avec la standardisation de HTML4, L'URL a perdu son statut d'adresse Web et a été rabaissée au simple rôle de composante. On a ainsi ajouté à l'URL une seconde composante, l'URN (Uniform Resource Name), pour former un tout qui s'appelle maintenant URI (Uniform Resource Identifier).
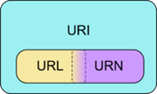
Par conséquent et contrairement à ce que l'on peut penser, une URL, comme par exemple http://www.google.fr, n'est aujourd'hui plus suffisante pour identifier une ressource de manière unique. C'est l'URN qui va ajouter à l'URL la partie manquante pour accéder à la ressource. Par exemple pour le fichier "cartefrance.html", l'URN sera " /cartefrance.html " et l'URI, qui est le moyen final d'accéder à la ressource, sera : http://www.google.fr/cartefrance .
Afin de fixer les idées, nous pouvons effectuer la comparaison entre une URI et une adresse postale classique. L'URI est comparable aux coordonnées complètes de la personne, l'URN à son nom et l'URL à son adresse.
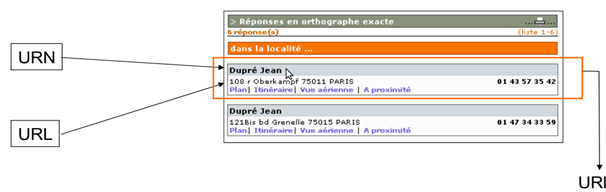
Voici donc le schéma complet d'une adresse Web
http://www.google.fr/178845/doc1
| <------- URL-------> | <-- URN --> |
| <----------------- URI ---------------> |
Cette notion d'URI est fondamentale car elle est devenue le système de référence d'identification des ressources Web dans les applications complexes tels que le sont les Web Services. L'URI est devenue la pierre angulaire de l'architecture Web.
Le système d'URI a été largement déployé depuis les débuts du Web et ses avantages sont nombreux : liens, favoris, mécanismes de cache, indexation par les moteurs de recherches, etc. . En utilisant les URI, il est possible de déployer une application partout dans le monde sans infrastructure additionnelle.
Après l'URL, c'est maintenant au tour de l'URI de laisser sa place !
Nouveau rebondissement dans le monde de l'adressage Web car après les URL, c'est au tour des URI de disparaître au profit d'une nouvelle recommandation du W3C. Les URI franchissent aujourd'hui elles aussi le cap de l'internationalisation et porteront désormais le nom d'IRI (Internationalized Resource Identifiers).
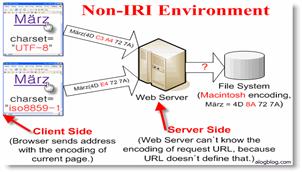
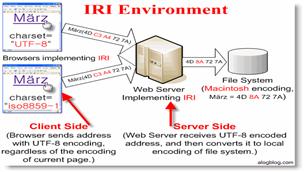
La raison des ces évolutions perpétuelles de l'URI vient du fait que ses spécifications, tout comme celles d'HTTP, sont apparues avant la création du W3C et leurs standardisations nécessitent donc une réadaptation continue sous peine de ne plus répondre aux besoins. Ce nouveau standard est, cette fois, destiné à combler les lacunes des URI causées par l'encodage des caractères qui diffère selon l'endroit où l'on se trouve sur la planète.
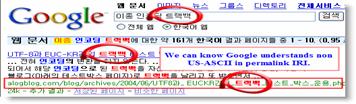
Selon la spécification IRI, chaque URI est déjà un IRI car la spécification IRI a été conçue pour pouvoir conserver les systèmes existants et elle ne perturbera donc en rien son fonctionnement actuel. Le grand changement tient dans le fait que ce standard permet maintenant aux développeurs d'écrire, à quelques exceptions près, les identificateurs de ressources (URN) dans leur propre langage et ce sera au système de se charger de la conversion.
 |
 |
Nous utiliserons dans la suite de ce mémoire le terme générique "URL" pour désigner l'adresse d'une ressource Web, sauf s'il est nécessaire d'effectuer la distinction.